In our previous post, we compared ID-Based and ID-Free recommendation models and found that ID-Free approaches generally produced higher-quality recommendations for personalized digital health nudging. In this post, we examine how ID-Free models behave under different conditions, focusing on three core questions:
1. How do ID-Free models scale as training data increases?
2. What trade-offs exist between recommendation quality, training time, and computational resources?
3. How much do semantic embeddings contribute, evaluated by comparing ID-Free and ID-Based versions of the same models?
To address these questions, we benchmarked several recommendation architectures powered by ID-Free semantic embeddings across varying training data sizes and conducted an ablation study contrasting each model’s ID-Free and ID-Based implementations.
Experiment Setup
We used the same proprietary digital health recommendation dataset as in our previous post. It consists of user–nudge interactions, enriched with metadata for both users (e.g., demographics, health conditions, aggregated tracker data) and nudges (e.g., content text, categories, target behaviors).
For all experiments, we maintained consistent validation and test sets, each covering one week of interaction data. The training data window was varied across 1, 2, 4, and 10 weeks to observe model behavior at different data volumes. Table 1 summarizes the dataset statistics for these splits.
| Split | # Users | # Nudges[1] | # Interactions |
|---|---|---|---|
| Train (1 week) | 2,334 | 56 | 3,158 |
| Train (2 weeks) | 4,176 | 56 | 6534 |
| Train (4 weeks) | 7,833 | 59 | 14,075 |
| Train (10 weeks) | 15,544 | 59 | 35,723 |
| Validation (1 week) | 2,285 | 70 | 3088 |
| Test (1 week) | 2,290 | 69 | 3,082 |
[1]Additional nudges were introduced in the production system during the validation and test periods, resulting in higher counts compared to the training splits.
Table 1: Dataset Statistics for train (1–10 weeks), validation, and test splits.
Model performance was evaluated using standard top-K recommendation metrics at K = 3:
• NDCG@3 (Normalized Discounted Cumulative Gain)
• Precision@3
• Recall@3
• MAP (Mean Average Precision)
The models we tested included:
• ID-Free Models: BPR, NeuMF, SimpleX, and SASRec, which leverage semantic embeddings derived from user and nudge metadata. These models span approaches from collaborative filtering to sequential modeling (see our previous post for details).
• ID-Based Counterparts: To isolate the impact of semantic embeddings, we implemented ID-based versions of the same models trained on discrete user and nudge IDs.
• Baselines: Two simple non-personalized models, Random and Popular, as benchmarks.
All models were trained using the same procedures and configurations described previously:
• Hyperparameter Tuning: Optimal hyperparameters for each model were selected by maximizing NDCG@3 on the validation set.
• Training and Evaluation: Models were trained until convergence, with early stopping to prevent overfitting. Final performance was measured on the held-out test set.
• Training Time: Training durations were recorded to assess computational efficiency across different training data sizes.
Scaling Up: Impact of Training Data Size on ID-Free Models
Understanding how recommendation models scale with varying amounts of training data is critical for real-world deployment, especially in dynamic environments like digital health, where user behavior and nudge content evolve rapidly. Models must perform adequately with limited historical interactions (e.g., for new users or nudges) while leveraging additional data as it becomes available.
We evaluated four ID-Free models — BPR, NeuMF, SimpleX, and SASRec — together with baselines across training windows from 1 to 10 weeks. Validation and test sets were held constant to isolate the effect of training volume. Our analysis examines both recommendation quality and training time, highlighting trade-offs between performance and computational cost.
Results & Key Observations
Model Performance by Training Window
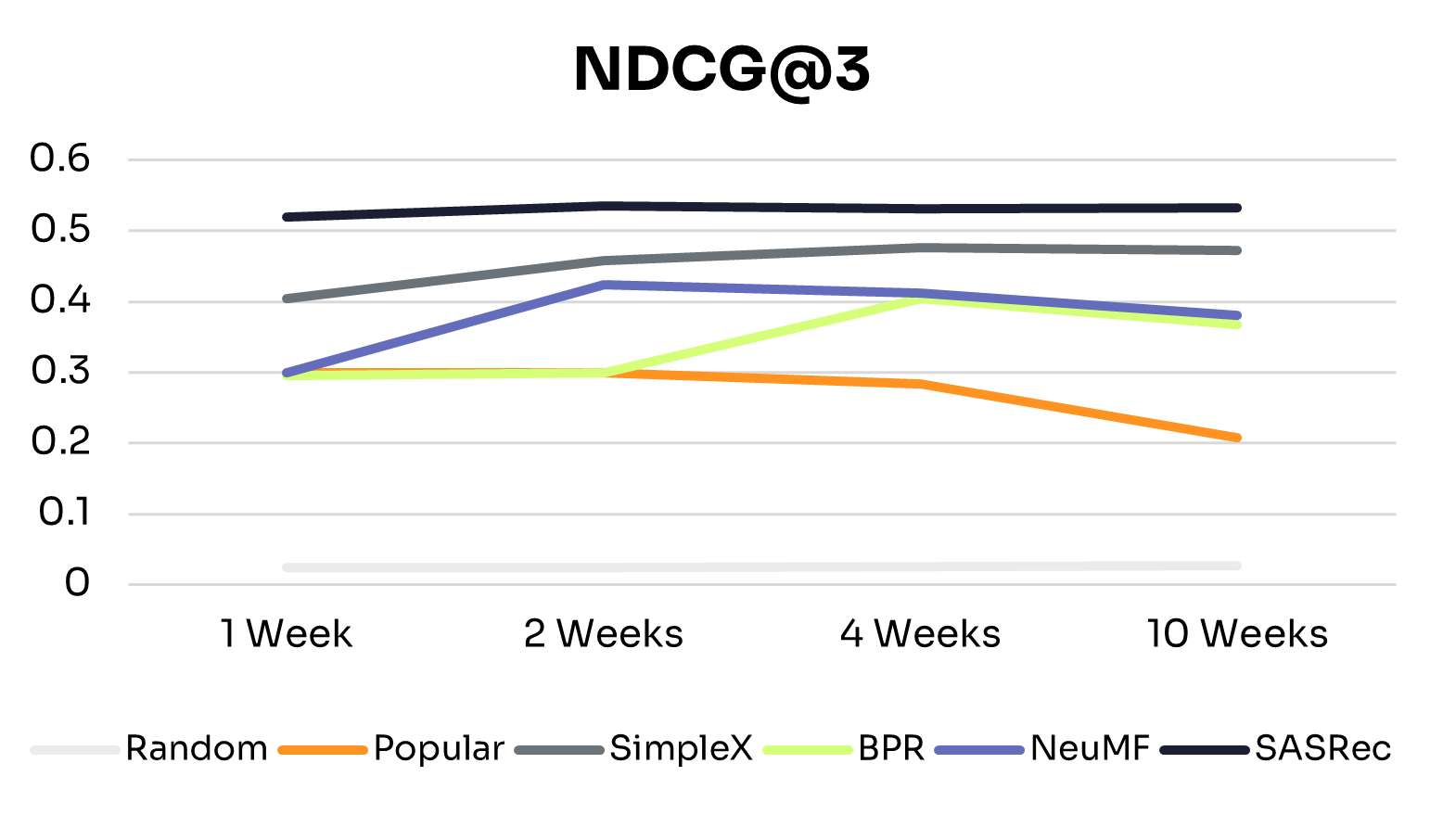
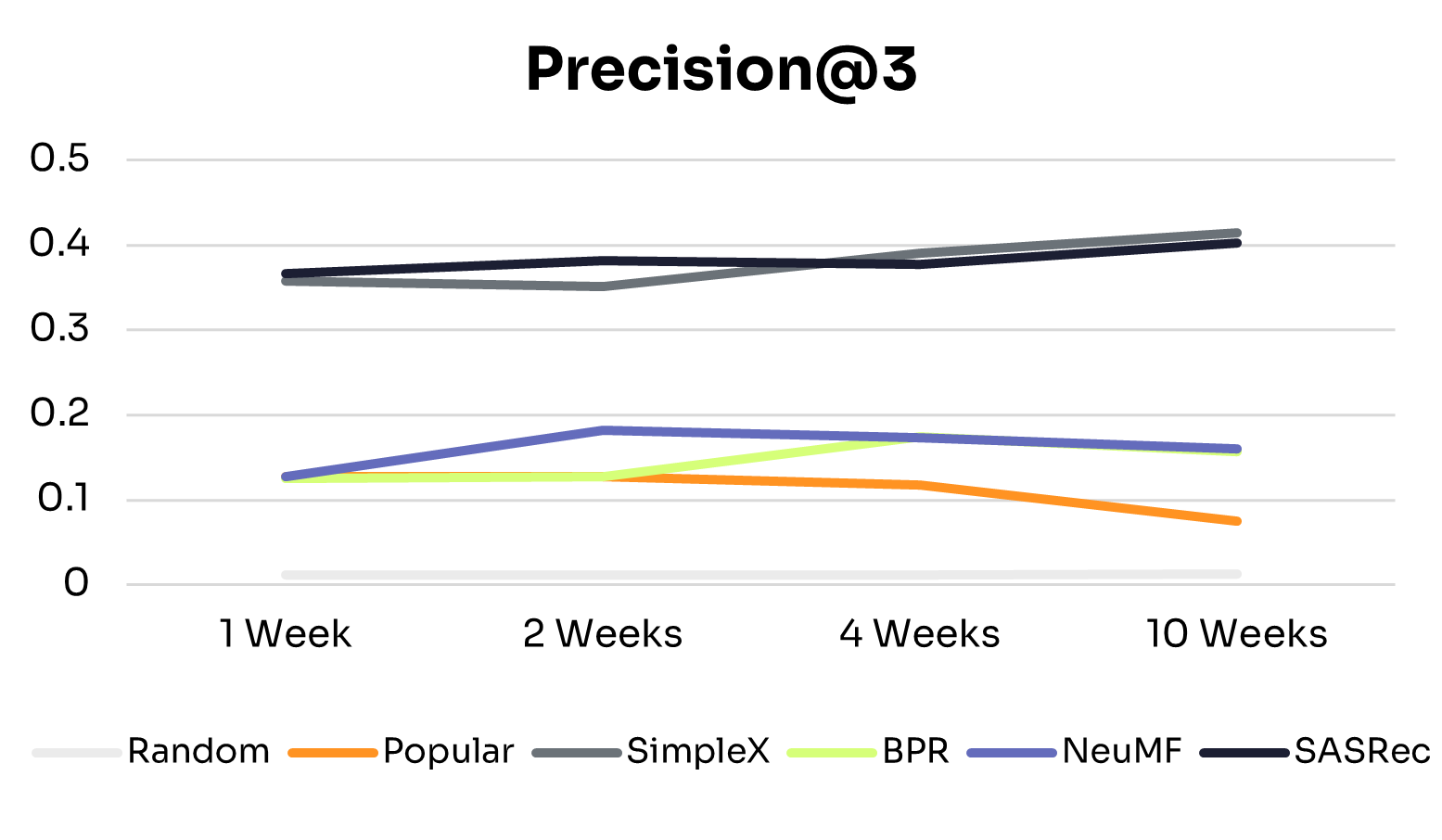
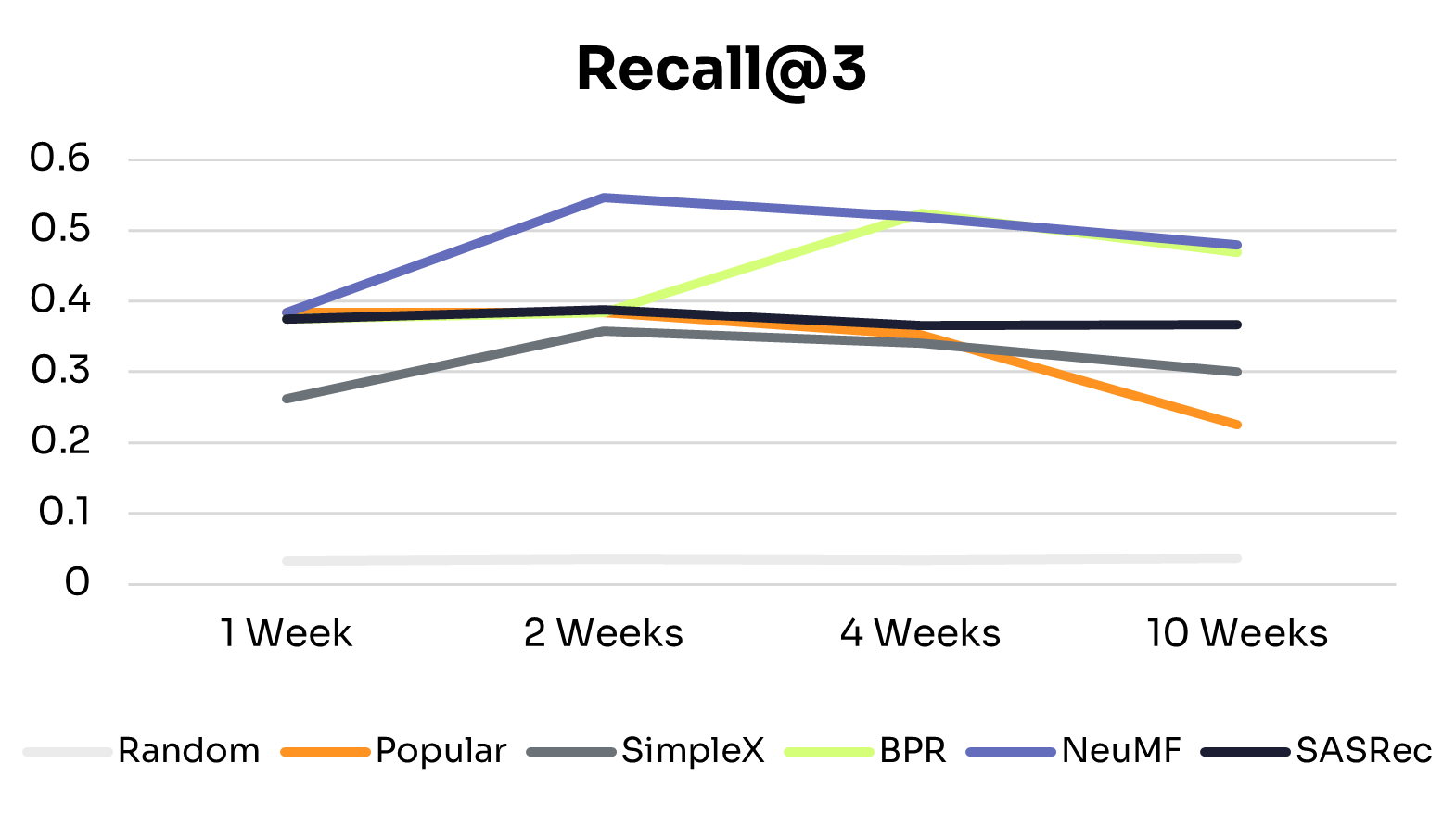
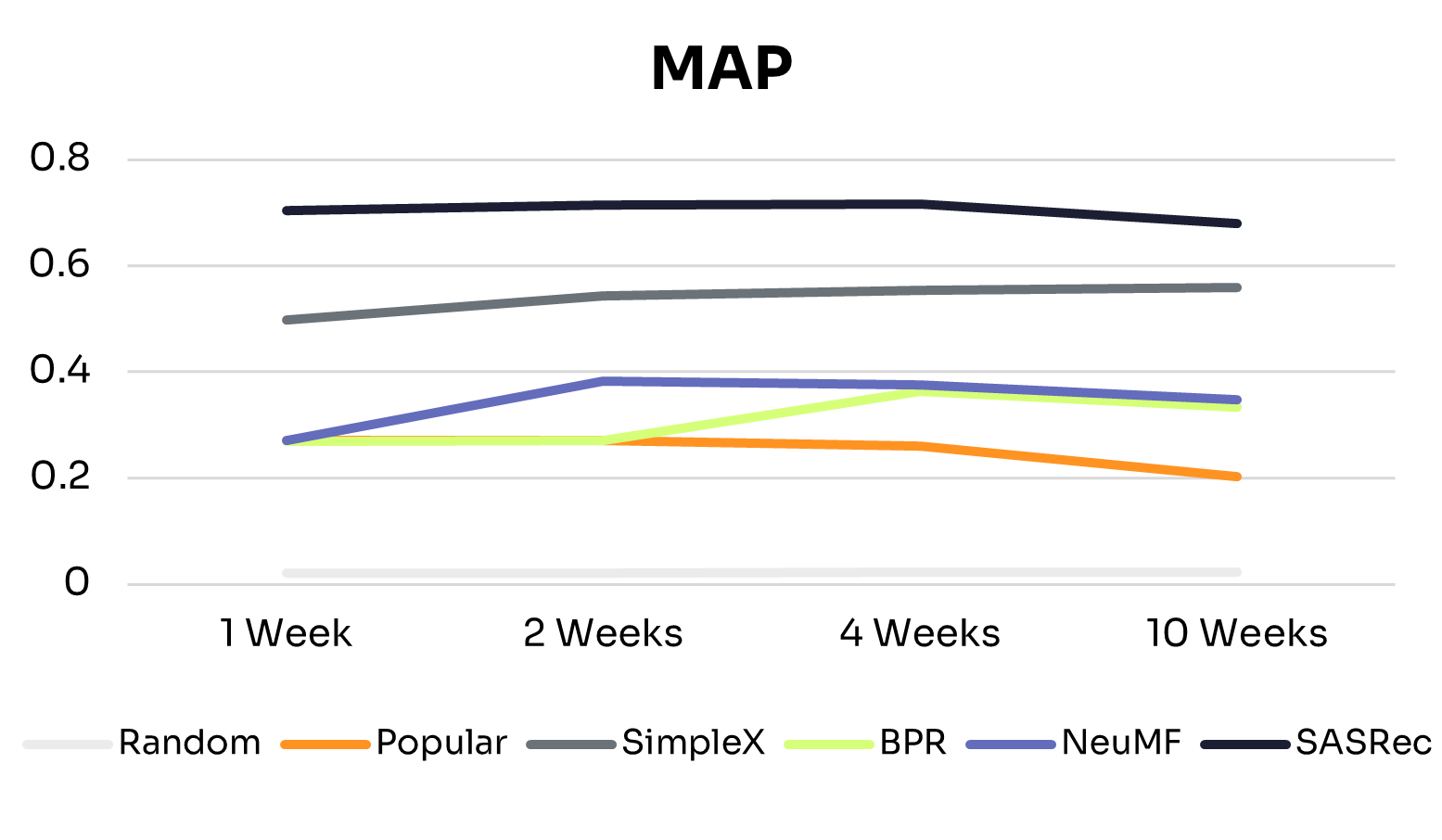
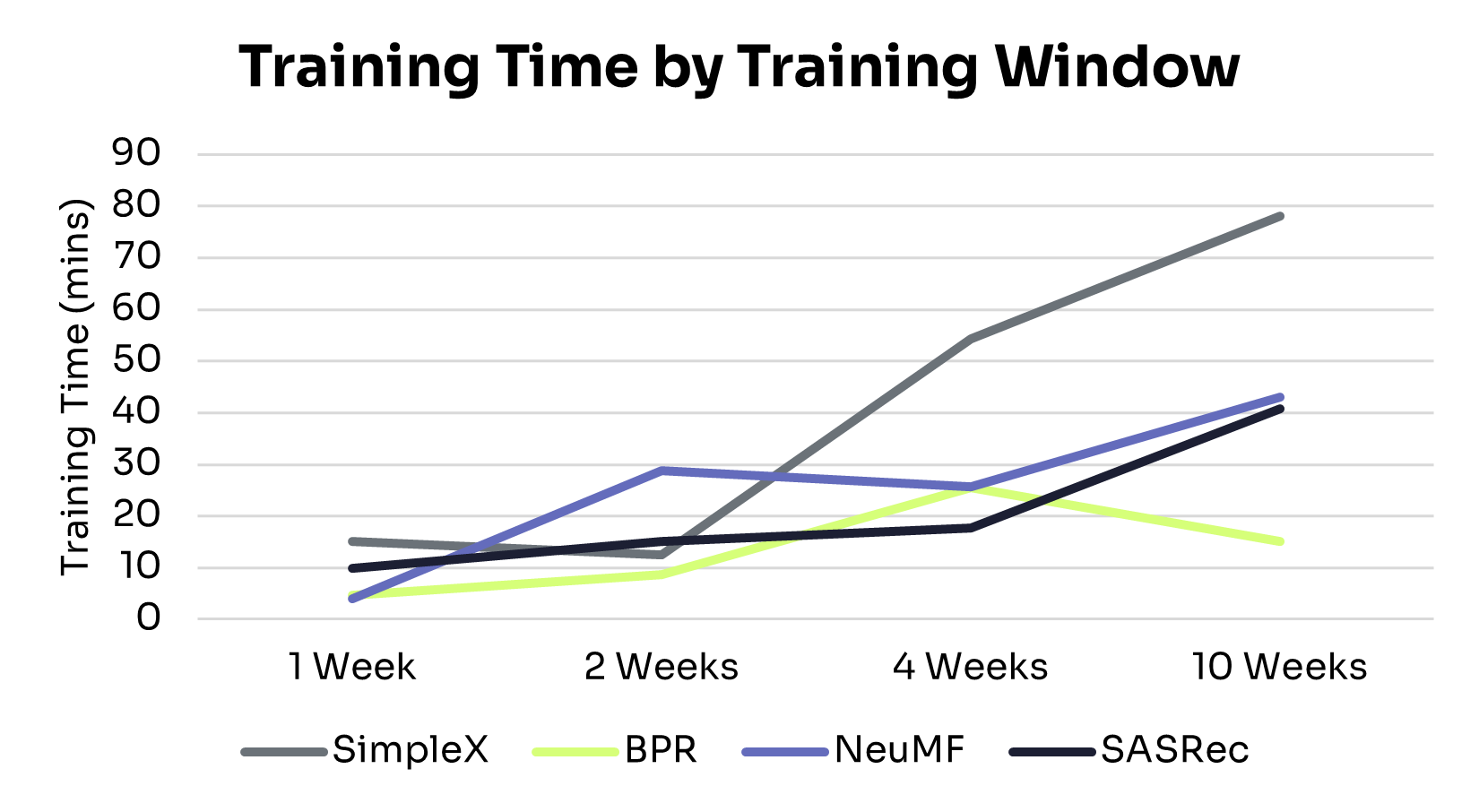
Figures 1 and 2 show how recommendation quality and training time vary across training windows.
Performance Relative to Baselines:
As expected, across all training windows, ID-Free models consistently outperformed the Random baseline. The Popular baseline performed better with small training windows but declined as training data increased, likely due to shifts in nudge popularity. This highlights the advantage of learned personalized models over static baselines.
General Scaling Behavior:
All ID-Free models improved across most metrics as training data increased from 1 to 4 weeks, suggesting they could learn richer patterns from additional interactions. Beyond 4 weeks, performance plateaued or declined slightly, indicating diminishing returns due to limited model capacity to exploit additional data or noise from older interactions.
Model-Specific Trends:
• BPR: The simplest model in the group, BPR peaked at 4 weeks and remained the lowest-performing model, suggesting that its pairwise ranking objective and limited capacity constrain generalization to larger, more diverse datasets.
• NeuMF: Peaked at 2 weeks, with slight declines at 4 and 10 weeks. Its hybrid architecture captures short-term patterns effectively, but without explicit temporal modeling, older interactions can introduce noise in longer histories.
• SimpleX: Showed consistent improvements from 1 to 10 weeks on NDCG@3, Precision@3, and MAP, with Recall@3 peaking at 2 weeks before tapering. This suggests that its sequence-aware architecture can extract long-term patterns while mitigating noise from older interactions.
• SASRec: The most stable and high-performing model across all training windows, performing well even with 1 week of data and maintaining or slightly improving performance up to 10 weeks. This reflects its ability to capture temporal dependencies effectively through sequential modeling and attention mechanisms.
These differences align with each model’s architecture: SimpleX and SASRec incorporate historical interactions directly into their scoring, whereas BPR and NeuMF do not. This structural difference likely explains why SimpleX and SASRec scale more effectively as data increases.
Computational Efficiency Trade-offs:
Training efficiency varied considerably across models as data volume increased. Here’s how they compare, from the most to least efficient:
• BPR: Minimal computational overhead, with training time under 30 minutes across all data sizes. Its limited capacity, however, constrains recommendation quality in larger or more complex datasets.
• SASRec: Balances performance and efficiency. Training time increased near-linearly with data volume, delivering strong recommendations without excessive cost.
• NeuMF: Training time grew more steeply than BPR and SASRec, with diminishing returns on performance. This makes it more suitable for short interaction windows or smaller datasets.
• SimpleX: Achieved strong performance gains but at the highest computational cost, with runtime rising sharply and surpassing all other models at the 10-week mark. This makes it best suited for settings with larger datasets and less constrained compute resources.
These trade-offs highlight the need to balance model performance and computational cost when selecting an architecture for production deployment.
Isolating the Impact of Semantic Embeddings: ID-Free vs. ID-Based
The previous section examined how ID-Free models scale with training data, but it did not isolate how much of their performance comes from semantic embeddings versus the model architecture itself. To address this, we conducted an ablation study comparing each model’s ID-Free variant (using semantic metadata) with its ID-Based counterpart (trained on discrete user and nudge IDs). This head-to-head setup directly measures the contribution of semantic embeddings across architectures.
Since most models performed best at the 4-week training window, we used this setting as the basis for the ablation.
Results & Key Observations
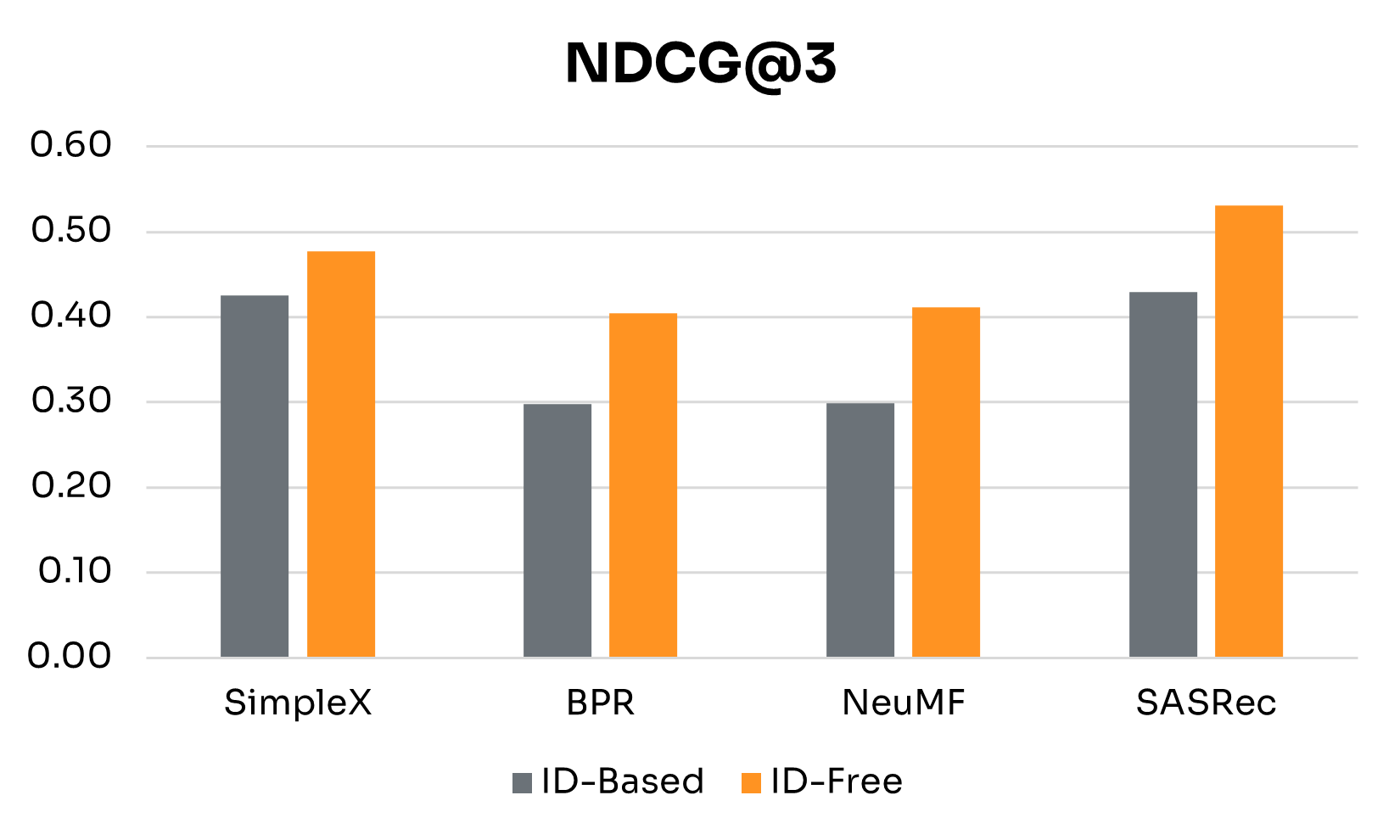
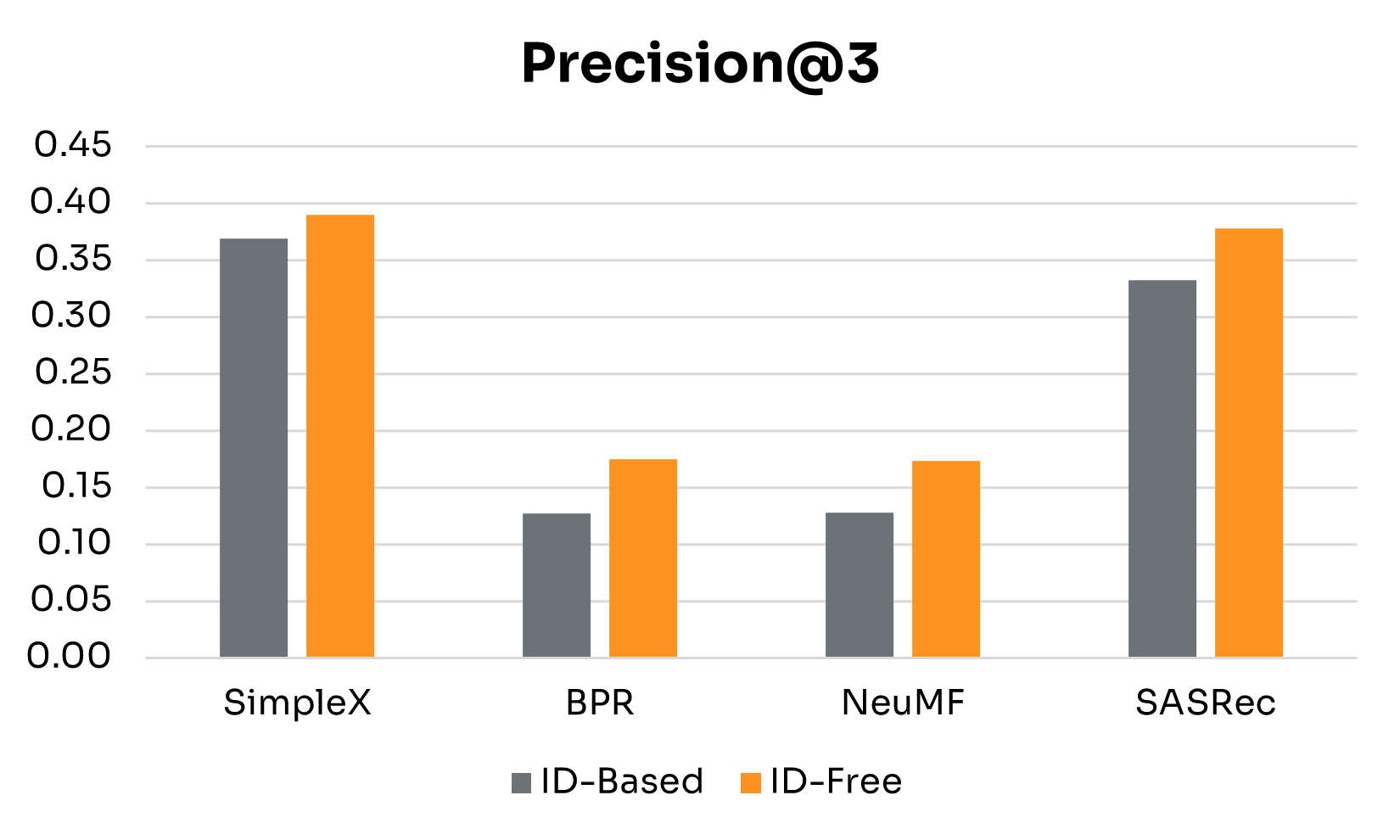
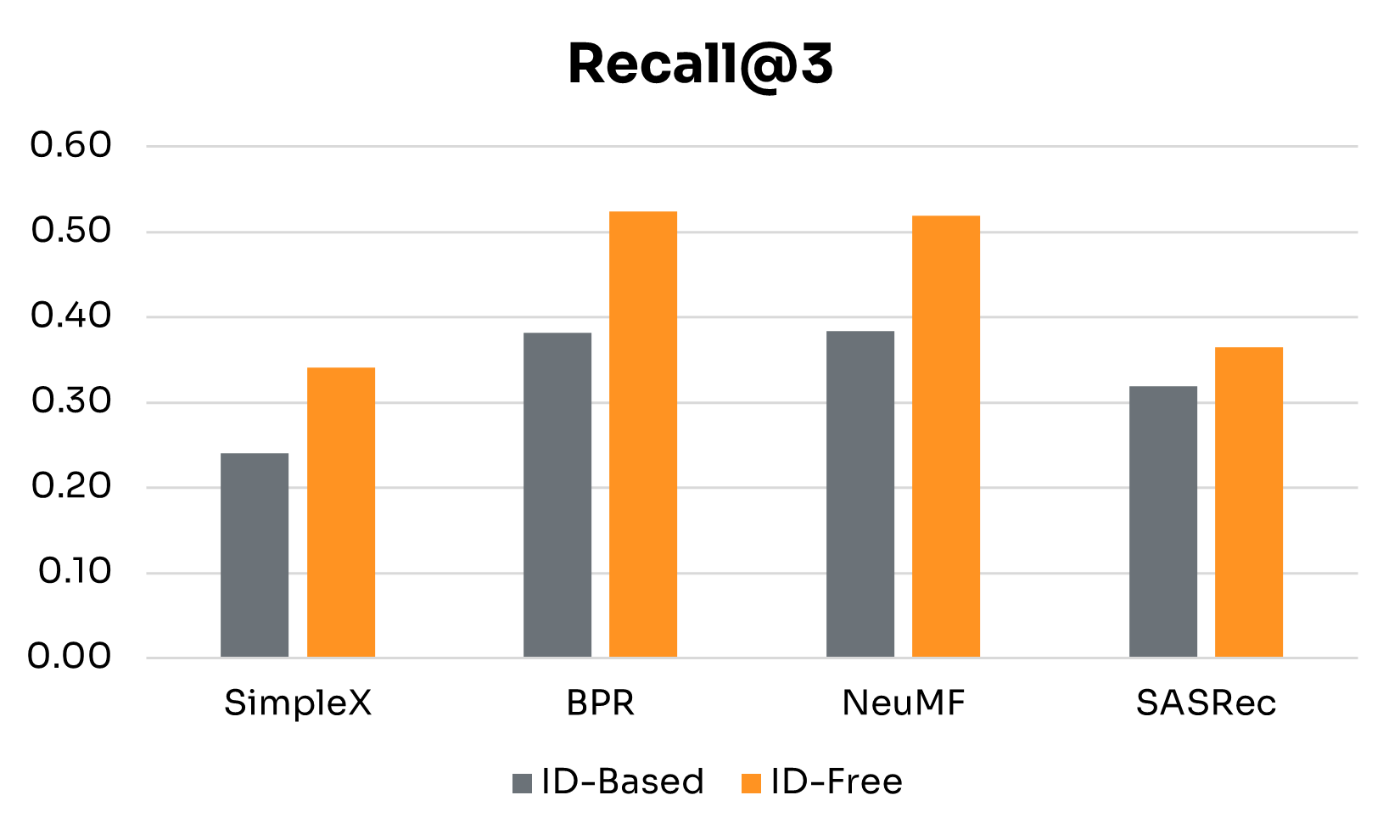
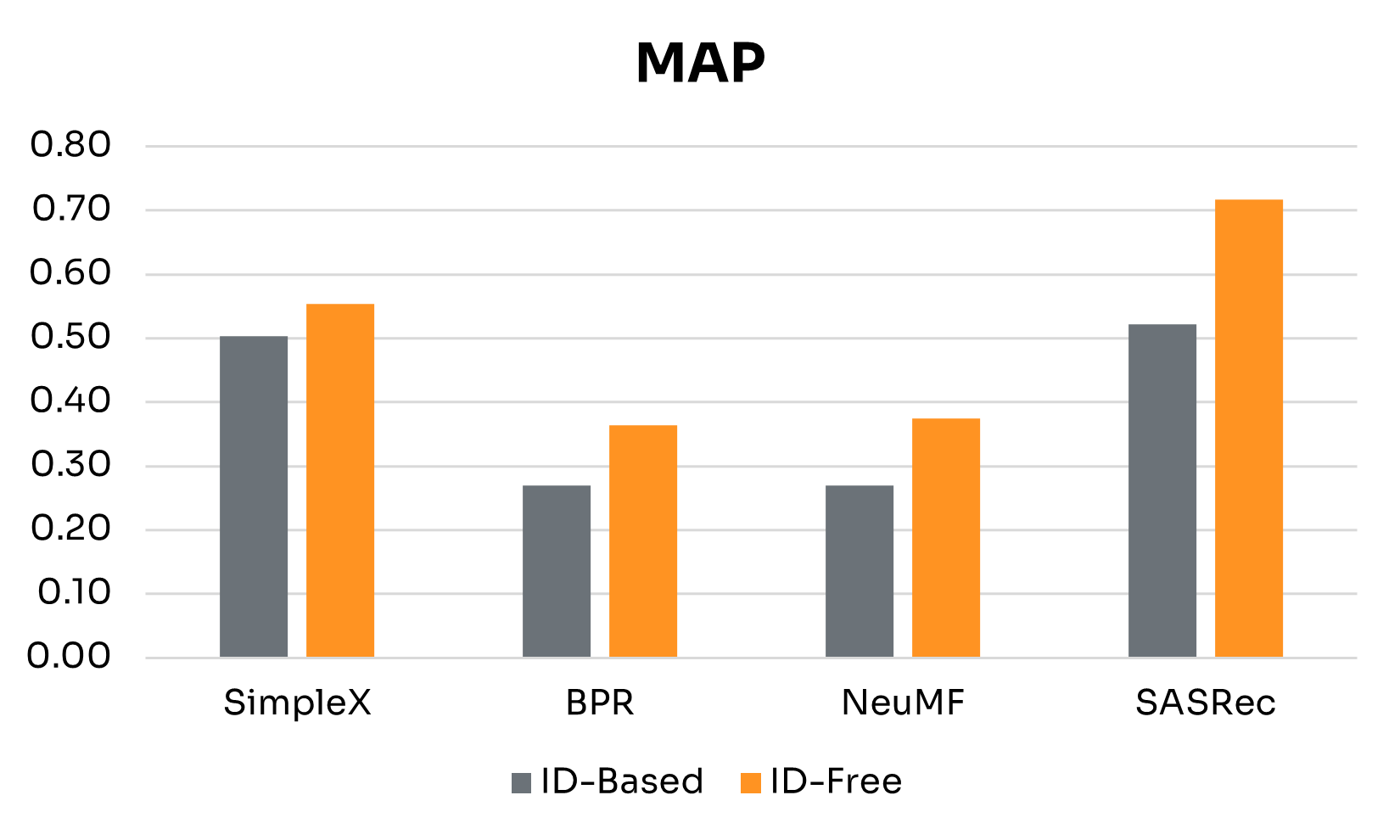
| Performance Gains | SimpleX | BPR | NeuMF | SASRec |
|---|---|---|---|---|
| NDCG@3 | 0.051 | 0.107 | 0.113 | 0.102 |
| Precision@3 | 0.021 | 0.047 | 0.045 | 0.045 |
| Recall@3 | 0.101 | 0.142 | 0.136 | 0.046 |
| MAP | 0.051 | 0.095 | 0.105 | 0.195 |
Figure 3 presents side-by-side results for ID-Free and ID-Based variants at the 4-week window. Table 2 summarizes detailed performance gains across key metrics. The main findings are:
• Semantic Embeddings Consistently Boost Performance: Across all four models, ID-Free variants outperformed ID-Based versions on every metric. This shows that embeddings derived from rich metadata capture more generalizable representations of users and nudges than raw IDs, yielding higher-quality recommendations regardless of architecture.
• Magnitude of Gains Depends on Architecture: BPR and NeuMF, the simpler non-sequential models, saw the largest boosts, especially in NDCG@3, Precision@3, and Recall@3. SimpleX showed more modest improvements, with its largest gain in Recall@3. SASRec recorded the biggest increase in MAP, though with smaller gains in Recall@3.
Overall, these results underscore the advantages of ID-Free modeling in dynamic, data-rich environments like digital health. By leveraging semantic embeddings, ID-Free models not only improve performance but also offer a more flexible and robust framework free from the constraints of traditional user and nudge identifiers.
Conclusion
This analysis highlights the real-world viability of ID-Free recommendation models. Performance generally improved with additional training data, peaking around the 4-week window. SASRec stood out as the most stable and consistently high-performing model, effectively capturing long-term user behavior through its sequential, attention-based architecture.
In terms of computational trade-offs, simpler models like BPR were highly efficient but limited in performance. SASRec provided the best balance of accuracy and efficiency, while SimpleX achieved strong results but at a much higher computational cost. The optimal choice depends on factors such as data availability, retraining frequency, and infrastructure constraints.
Most importantly, the ablation study demonstrated that semantic embeddings consistently improved performance across all architectures. This indicates that the strength of ID-Free models lies not only in their design but in their ability to capture richer, more generalizable representations of users and nudges. Together, these findings position ID-Free approaches as a strong candidate for digital health recommendation systems, offering adaptability to cold-start scenarios and enabling robust, high-quality personalization.
Author:

Jodi Jodi is a Data Scientist at CueZen, where she develops machine learning models to improve engagement and drive positive health behaviors.