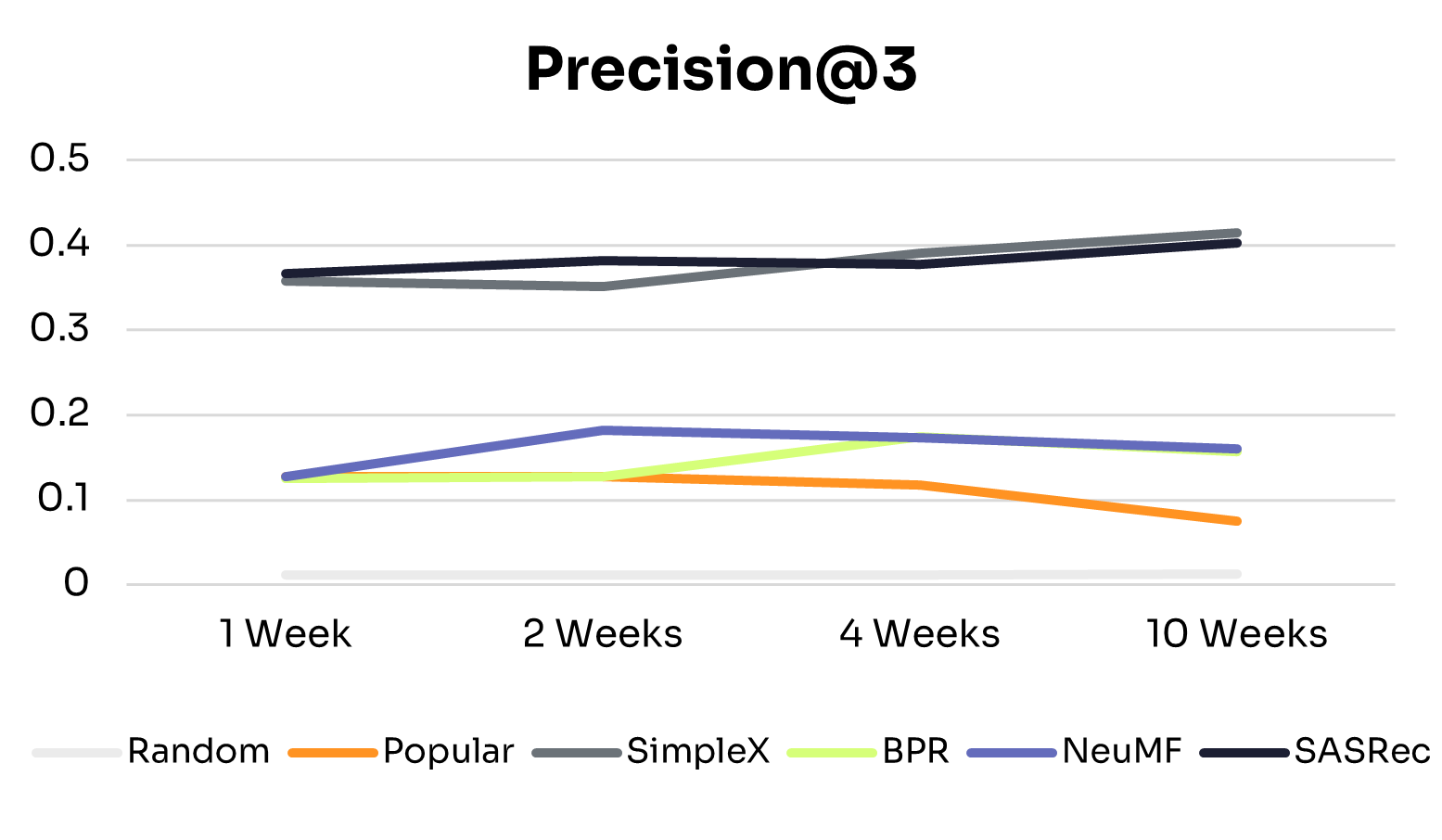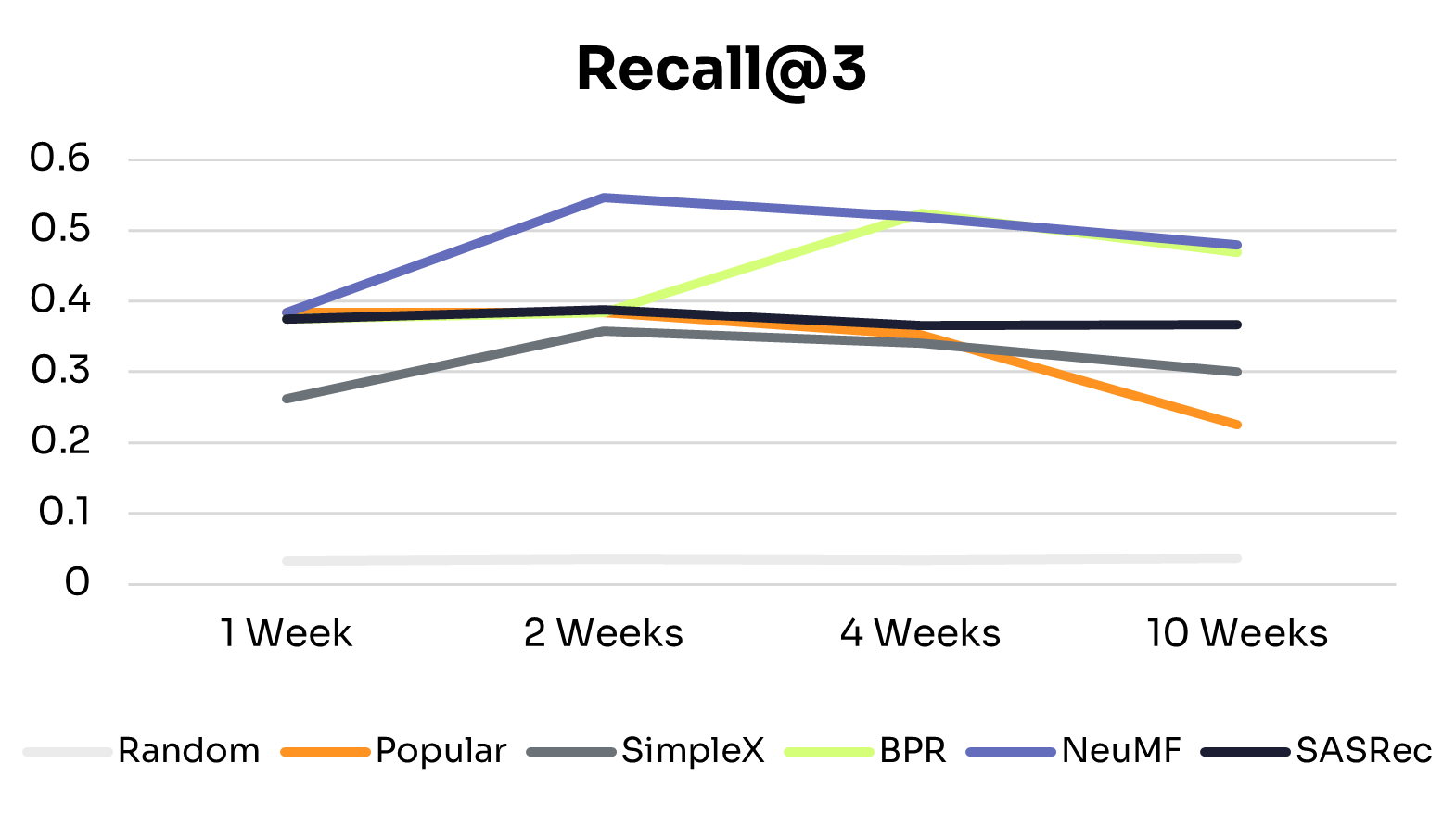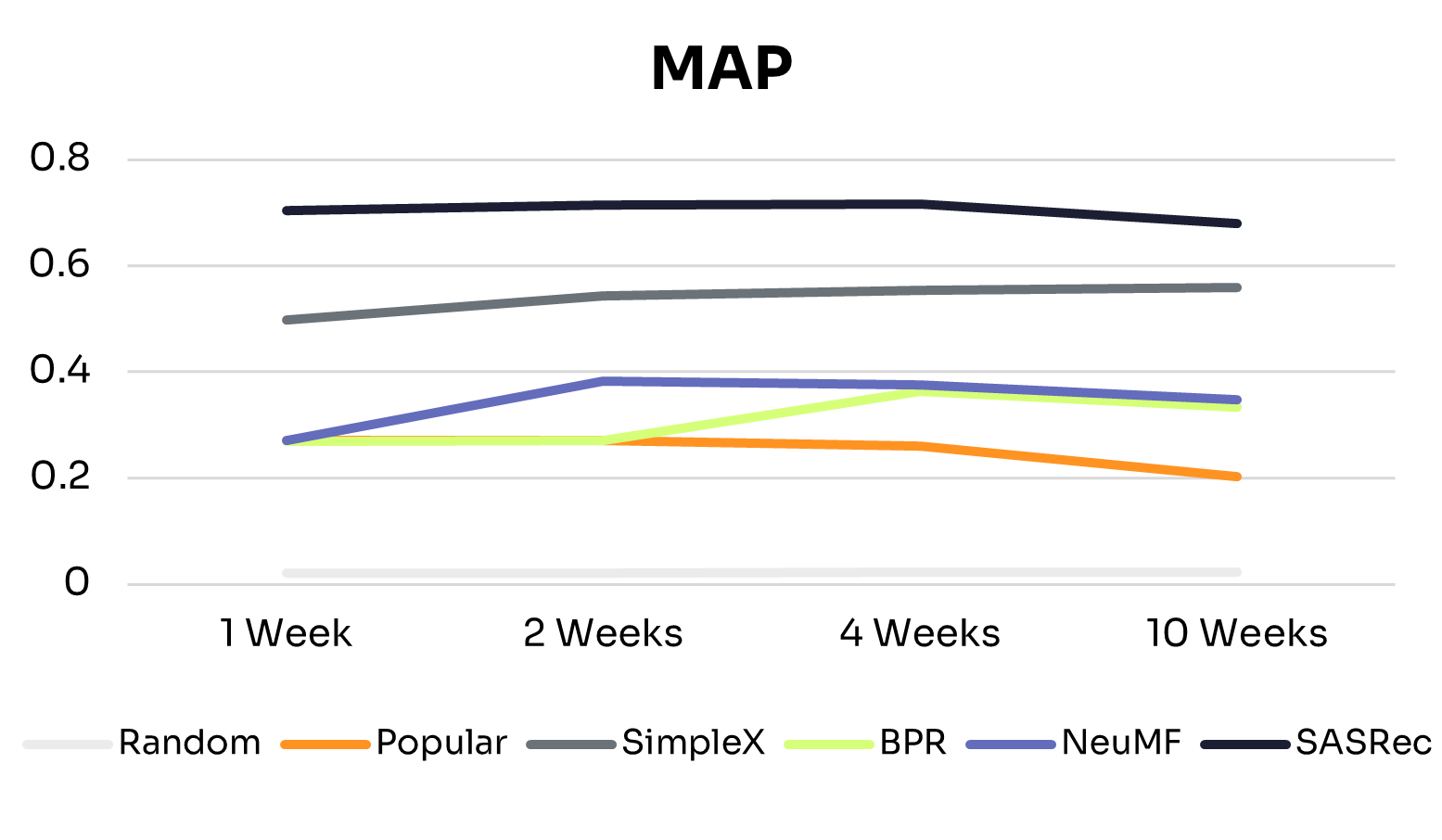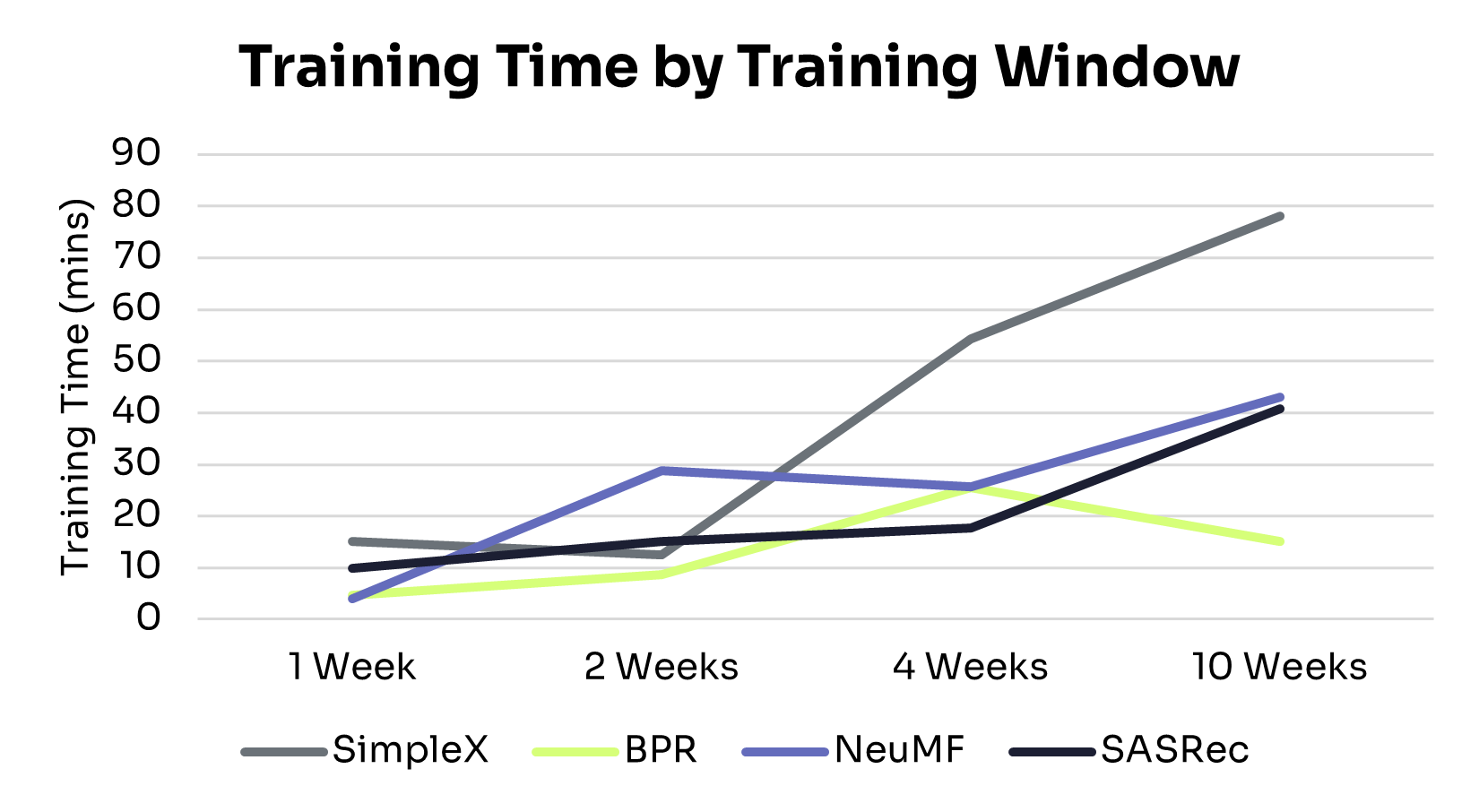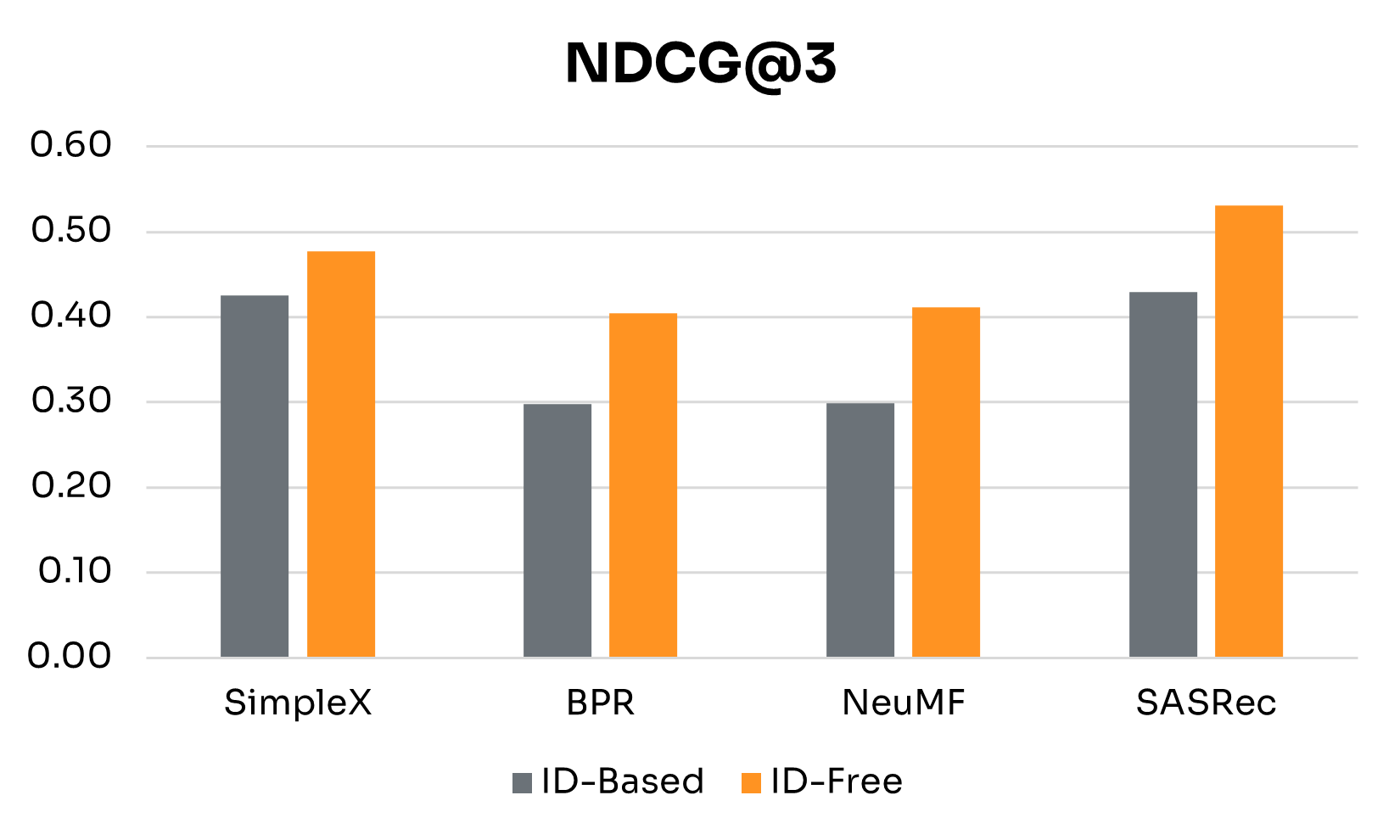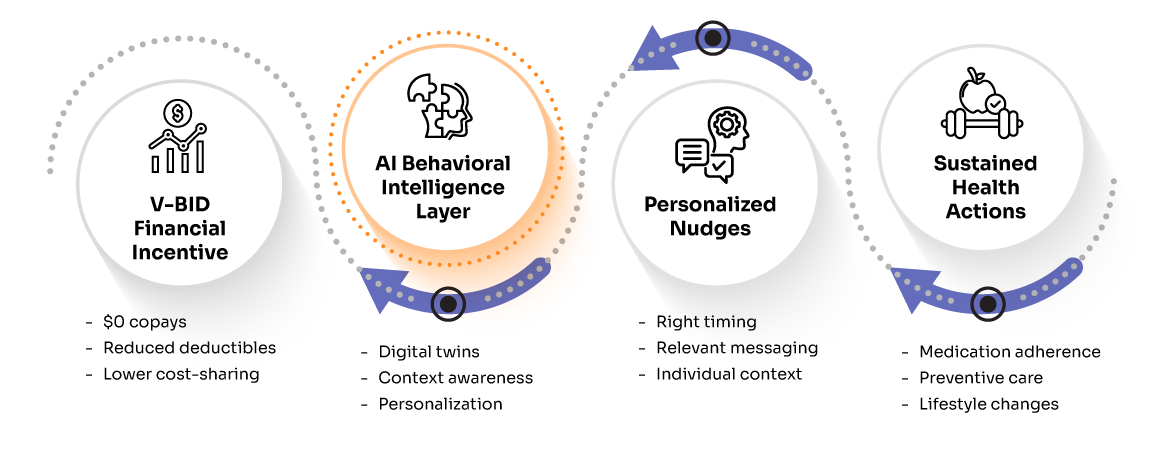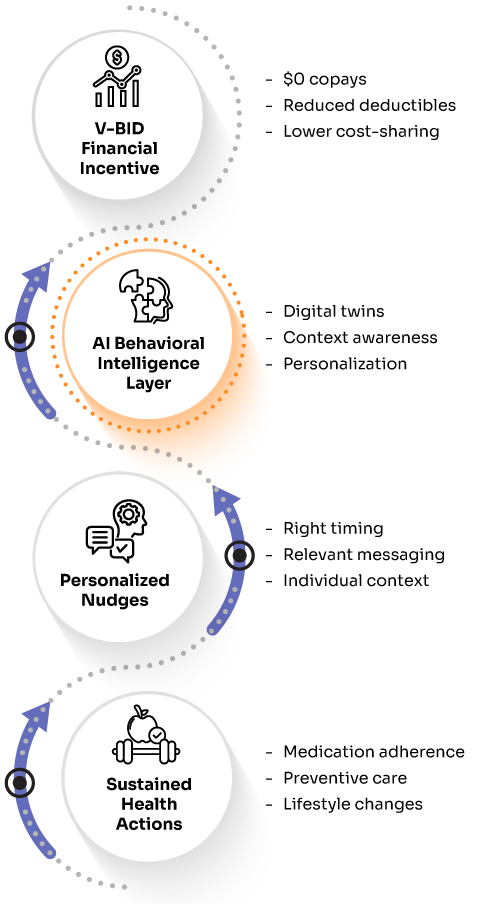


The holy grail of health AI has always been personalization at scale: delivering the right intervention, to the right person, at the right time, across millions of users simultaneously. For years, this remained elusive. Traditional recommendation systems that worked beautifully for e-commerce and entertainment hit fundamental barriers when applied to health behavior change.
The breakthrough came not from scaling existing approaches, but from recognizing that health personalization requires a fundamentally different architecture—one that can model complex relationships between users, behaviors, interventions, and contextual factors in real-time. Enter Graph Neural Networks augmented with dynamic Knowledge Graphs.
The Traditional Health AI Cold Start Problem
Most health recommendation systems rely on collaborative filtering or content-based approaches adapted from e-commerce. But health behavior presents unique challenges that break these traditional models:
Sparse Interaction Data: Unlike e-commerce where users generate hundreds of implicit signals (clicks, views, purchases), health interventions generate sparse feedback. A user might interact with a health nudge only once per day, creating a data sparsity problem that collaborative filtering struggles to handle.
Context Criticality: The same intervention that motivates a user in the morning might be ignored or even counterproductive in the evening. Traditional matrix factorization approaches cannot capture these temporal and contextual dependencies effectively.
Cold Start Complexity: New users in health apps often have minimal interaction history but rich demographic and health data. Traditional systems struggle to leverage this heterogeneous information effectively.
Multi-Modal Integration: Health decisions are influenced by physiological data (heart rate, sleep), behavioral patterns (exercise history), environmental factors (weather, location), and social context [9]. Traditional recommender architectures aren’t designed for this level of multi-modal integration.
These limitations aren’t just theoretical—they represent the difference between a system that works in research settings and one that can drive sustained behavior change at population scale.
The GNN + Knowledge Graph Architecture
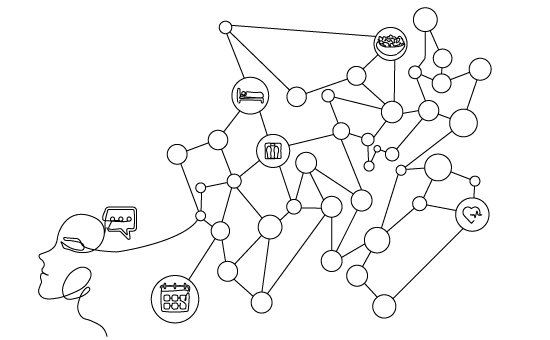
The solution emerged from recognizing that health personalization is fundamentally a graph problem. Users, interventions, behaviors, and contextual factors form a complex network of relationships that evolve continuously. Graph Neural Networks provide the perfect framework for modeling these relationships and propagating information across the network.
Core Architecture Components
Dynamic Knowledge Graph Construction: Rather than static user-item matrices, the system constructs a heterogeneous knowledge graph where nodes represent users, interventions, behavioral markers, and contextual factors. Edges capture relationships like “user has characteristic,” “intervention targets behavior,” or “user interacted with intervention.”
The knowledge graph schema typically includes:
• User nodes: Demographics, health status, behavioral patterns
• Intervention nodes: Nudges, recommendations, educational content
• Behavioral marker nodes: Activity levels, health metrics, engagement patterns
• Contextual nodes: Time-of-day, weather conditions, social settings
• Relationship edges: Interactions, similarities, targeting rules, temporal associations
Attentive Graph Convolution: The GNN employs attention mechanisms to learn which relationships are most important for each prediction. Knowledge-aware attention specifically considers the semantic meaning of different edge types, allowing the model to weight relationships appropriately.
The attention mechanism uses relation-specific transformations [2]:
α(r,a,b) = softmax_b((W_r * e_b)^T * tanh(W_r * e_a + e_r))
Where W_r is a relation-specific transformation matrix, e_a and e_b are node embeddings, and e_r is the relation embedding.
Real-Time Adaptation: Unlike static models that require periodic retraining, the system continuously updates node embeddings as new interaction data arrives. This enables the model to adapt to changing user preferences and behaviors in near real-time.
Multi-Scale Personalization: The architecture supports personalization at multiple levels—from individual user preferences to population-level patterns—by aggregating information across different numbers of graph hops.
Technical Innovation Points
Handling Heterogeneous Data: Traditional GNNs assume homogeneous node types. Health applications require handling users, interventions, and contextual factors as fundamentally different entity types with different feature spaces. The solution involves type-specific embedding layers and attention mechanisms.
Temporal Dynamics: User health states and preferences evolve continuously. The architecture addresses this through time-aware embeddings and decay mechanisms that reduce the influence of outdated interactions.
Scalability Engineering: Population-scale deployment requires processing millions of nodes and edges efficiently. Key optimizations include:
• Parallel batch processing with automatic retry mechanisms
• Distributed graph storage with locality-aware partitioning
• Efficient sampling strategies for large neighborhoods
• Incremental embedding updates to avoid full recomputation
Production Deployment Considerations
Privacy-Preserving Design: Health data requires advanced privacy protection. The system operates on pseudonymized identifiers and can be deployed in air-gapped environments with no external data transfer.
Fault Tolerance: Clinical applications demand high reliability. The architecture includes automated retry mechanisms, batch-level failure recovery, and comprehensive monitoring across graph construction, model inference, and recommendation delivery pipelines.
Regulatory Compliance: Healthcare deployments require audit trails and explainability. The attention mechanisms provide natural interpretation paths by highlighting which relationships contributed most to each recommendation.
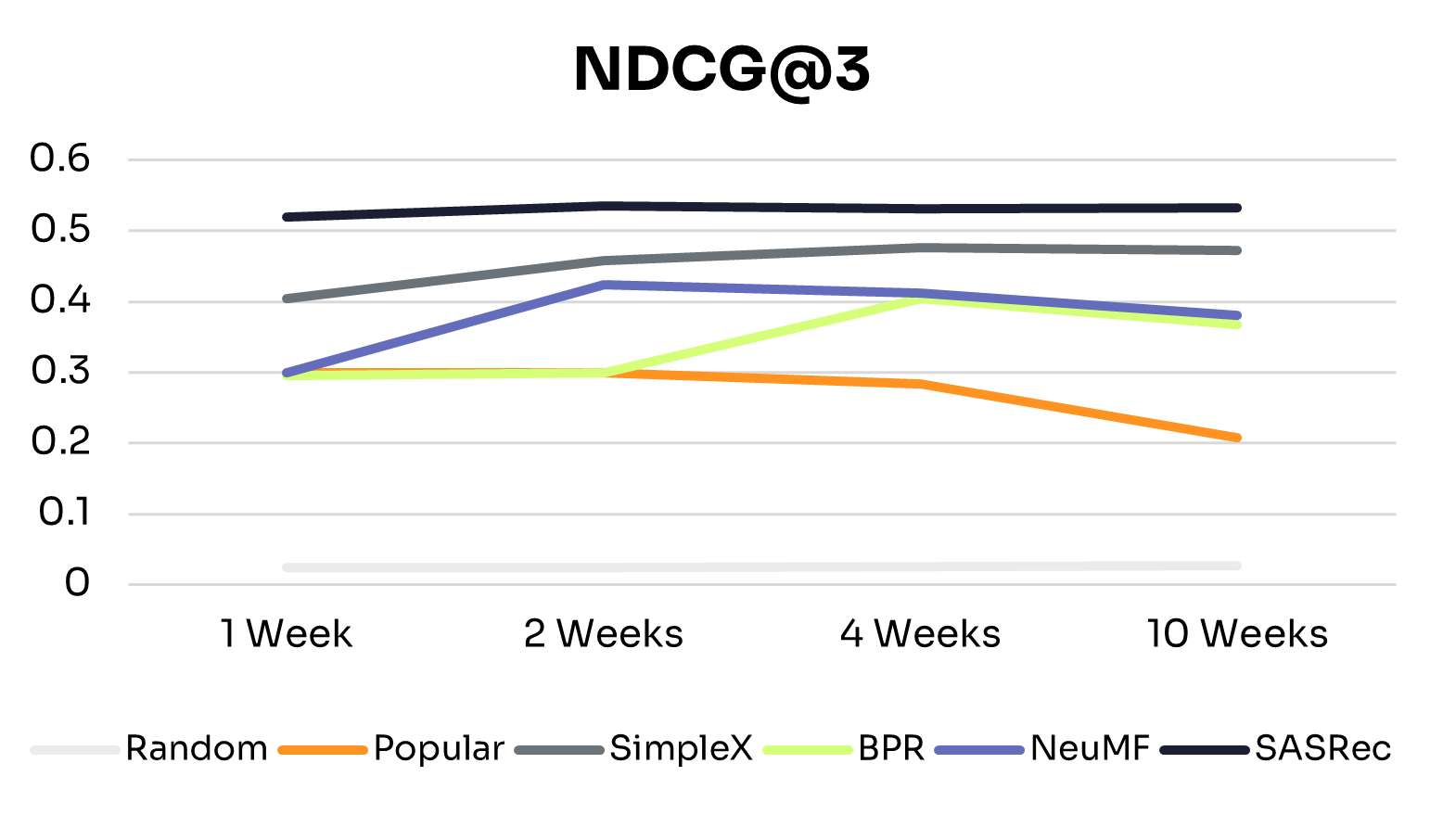
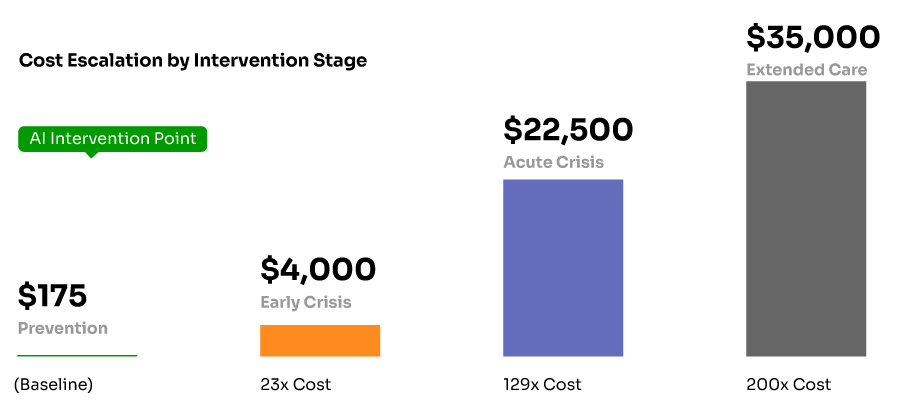
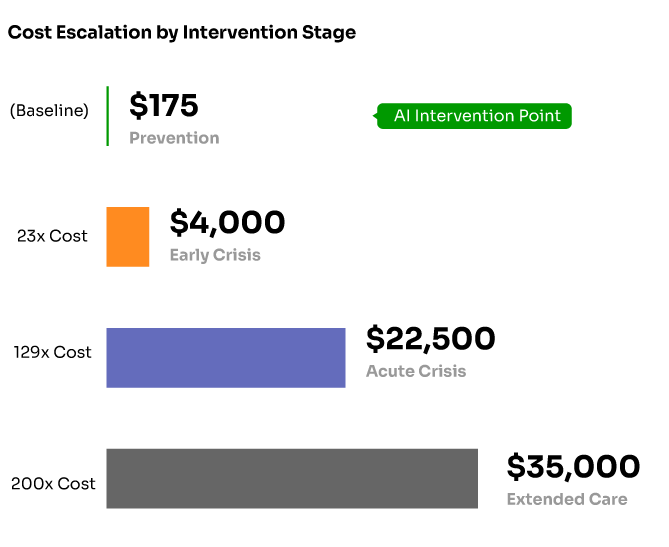
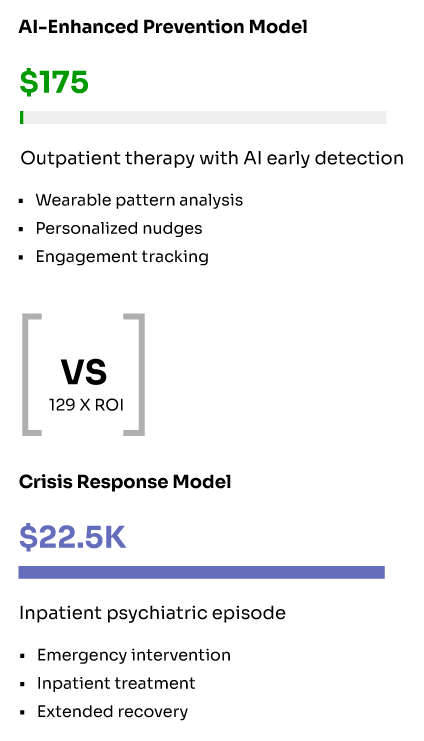
Verified Performance Results
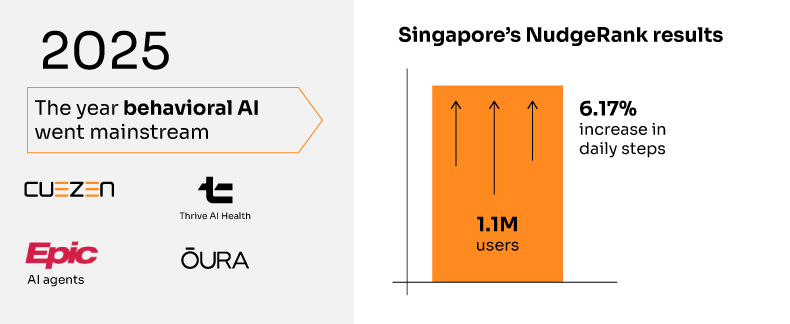
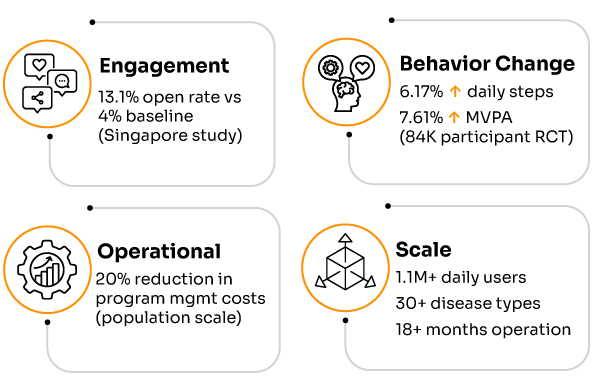
Academic literature provides concrete evidence of GNN effectiveness in health applications. Research published in KDD 2024 documents a production system serving over 1 million users daily with the following validated results [1]:
Model Performance: Precision@3 of 0.0501 for predicting user interactions with health interventions, with stable performance over 4-month production deployment (standard deviation < 0.007 across daily model updates) [1].
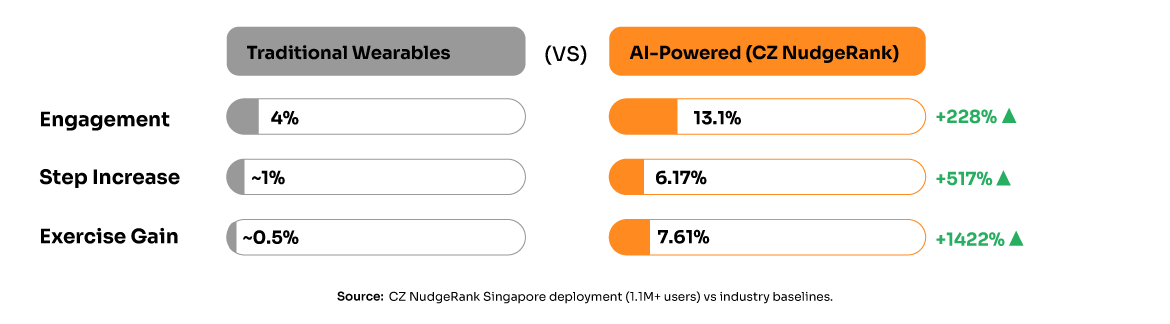
Behavioral Impact: Controlled studies demonstrate statistically significant improvements in health behaviors [1]:
• 6.17% increase in daily physical activity (p = 3.09 × 10^-4)
• 7.61% increase in weekly exercise duration (p = 1.16 × 10^-2)
• 13.1% engagement rate compared to 4% baseline for traditional approaches
Scalability Validation: Linear scaling demonstrated from 300,000 to 19 billion candidate user-intervention pairs, with strong correlation (R² = 0.9997) between dataset size and processing time on commodity hardware [1].
System Reliability: 18+ months of continuous operation with automated daily model updates completing in 90-150 minutes, demonstrating production-grade stability [1].
Technical Challenges Solved
Dynamic Graph Updates: Traditional GNN implementations assume static graphs. Health applications require continuous graph evolution as users’ health states change. The solution involves efficient incremental embedding updates and change propagation algorithms.
Multi-Modal Feature Integration: Combining physiological sensor data, demographic information, and behavioral patterns requires careful feature engineering and attention mechanisms that can weight different modalities appropriately.
Real-Time Inference: Generating personalized recommendations for millions of users daily requires optimized inference pipelines. Key innovations include pre-computed user embeddings, efficient candidate generation, and distributed serving architectures.
Cold Start with Rich Context: New users lack interaction history but often have rich demographic and health data. The GNN architecture solves this by propagating information from similar users through the graph, enabling immediate personalization based on shared characteristics and goals.
Industry Applications and Future Directions
The success of GNN-based health personalization has catalyzed broader industry adoption. Epic’s 2025 launch of AI agents for personalized medicine signals enterprise healthcare systems are moving toward graph-based architectures for clinical decision support [3]. With 65% of US hospitals already using predictive models [4], the foundation for graph-based health AI is accelerating.
Consumer health platforms are increasingly adopting similar approaches. Major wearable manufacturers are integrating graph-based models for activity recommendations, while chronic disease management apps use knowledge graphs to model complex comorbidity relationships [5].
Emerging Technical Frontiers:
Federated Graph Learning: Multiple healthcare organizations can collaboratively train models without sharing patient data, using federated learning techniques adapted for graph neural networks.
Multimodal Graph Fusion: Integration of speech pattern analysis, social media sentiment, and biometric data into unified graph representations for more comprehensive health modeling.
Causal Graph Discovery: Moving beyond correlation to identify causal relationships in health behavior networks, enabling more effective intervention design.
Temporal Graph Networks: Advanced architectures that explicitly model how health relationships evolve over time, improving long-term outcome prediction.
The convergence of proven GNN architectures, scalable graph processing infrastructure, and validated health applications creates unprecedented opportunities for technical innovation in healthcare AI. For technical leaders, the question isn’t whether to adopt graph-based approaches—it’s how quickly you can adapt them to your specific health domain.
Enhanced Industry Signals/Case Studies for Technical Audience
Enterprise Healthcare AI Deployments
Epic’s AI Agent Architecture: Healthcare’s largest EHR provider is deploying AI agents for personalized medicine at scale [3], with 65% of US hospitals already using predictive models [4]. The architecture emphasizes real-time treatment adjustment based on continuous monitoring, suggesting graph-based approaches for modeling patient-provider-treatment relationships.
Clinical Decision Support Systems: Mount Sinai’s deployment of AI delirium prediction represents the first AI model demonstrating real-world clinical benefits beyond laboratory performance [6]. The system integrates multiple data streams (vitals, medications, lab results) in ways that suggest knowledge graph architectures for relationship modeling.
Consumer Platform Technical Innovations
Wearable Data Integration: Major platforms (Oura, WHOOP, Apple) are competing on AI-powered behavioral insights that require processing multimodal sensor streams. Technical requirements include:
• Real-time biometric data processing (heart rate variability, sleep stages, activity patterns)
• Context-aware recommendation engines that adapt to circadian rhythms
• Privacy-preserving on-device inference for sensitive health data
Conversational Health AI: The emergence of LLM-powered health coaches (Thrive AI Health, various startups) creates new technical challenges:
• Integrating structured health data with unstructured conversation
• Maintaining conversation context across multiple health domains
• Ensuring medical accuracy while enabling natural language interaction
Advanced Research Implementations
Google Health AI Initiatives: The 2025 AI for Health cohort showcases cutting-edge technical approaches [7]:
• Facial Expression Analysis: Computer vision models for mental health assessment requiring real-time video processing and privacy protection
• Smartphone Health Screening: 2-minute health assessments using device sensors for early diagnosis, demonstrating edge AI capabilities
• Multimodal Health Monitoring: Integration of audio, visual, and sensor data for comprehensive health state assessment
Federated Learning in Healthcare: Growing adoption of privacy-preserving collaborative learning where multiple healthcare organizations train shared models without data centralization. Technical challenges include:
• Handling non-IID data distributions across healthcare systems
• Maintaining model quality while preserving privacy
• Coordinating updates across heterogeneous infrastructure
Open Source and Standards
Health Data Standards Integration: FHIR (Fast Healthcare Interoperability Resources) adoption is accelerating, creating opportunities for standardized health knowledge graph schemas. Technical implications include:
• Standardized data models for cross-system interoperability
• Graph database optimizations for FHIR resource relationships
• Real-time data synchronization across healthcare systems
Privacy-Preserving Technologies: Advanced cryptographic techniques becoming practical for health AI:
• Homomorphic Encryption: Computation on encrypted health data
• Secure Multi-Party Computation: Collaborative analysis without data sharing
• Differential Privacy: Mathematical privacy guarantees for population health studies
Performance Benchmarking
Scalability Comparisons: Industry benchmarks emerging for health AI systems:
• Latency requirements: <100ms for real-time recommendations
• Throughput targets: Processing millions of users daily
• Accuracy baselines: Precision@K metrics for health intervention recommendations
• Resource efficiency: Cost per user per day for cloud deployments
Model Architecture Evolution: Technical trends in health AI architectures:
• Migration from collaborative filtering to graph neural networks
• Adoption of transformer architectures for sequential health data
• Integration of causal inference techniques for intervention design
• Multi-task learning for simultaneous health outcome prediction
This technical landscape represents the convergence of advanced AI research with practical healthcare deployment requirements. For engineering teams, success requires balancing algorithmic sophistication with regulatory compliance, privacy protection, and clinical safety standards.
References
[1] Chiam, J., Lim, A., & Teredesai, A. (2024). NudgeRank: Digital Algorithmic Nudging for Personalized Health. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24).
[2] Wang, X., He, X., Cao, Y., Liu, M., & Chua, T. S. (2019). KGAT: Knowledge graph attention network for recommendation. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 950-958.
[3] Reich, V. (2025). 2025: AI enhances personalized care; caregiver experience in spotlight. Healthcare IT News. Retrieved from https://www.healthcareitnews.com/news/2025-ai-enhances-personalized-care-caregiver-experience-spotlight
[4] Multiple authors (2025). Current Use of AI and Predictive Models in US Hospitals. Health Affairs, 44(1). https://doi.org/10.1377/hlthaff.2024.00842
[5] Breen, J. (2024). AI Health Coaches Unlock Personalized Insights. Fitt Insider. Retrieved from https://insider.fitt.co/ai-health-coaches-unlock-personalized-insights/
[6] Friedman, C., et al. (2025). AI Model Improves Delirium Prediction. JAMA Network Open. Mount Sinai Press Release: https://www.mountsinai.org/about/newsroom/2025/ai-model-improves-delirium-prediction
[7] Google Team (2025). Google’s 2025 Growth Academy: AI for Health cohort. Google Blog. Retrieved from https://blog.google/outreach-initiatives/entrepreneurs/growth-academy-ai-health-2025/
[8] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., & Bengio, Y. (2017). Graph attention networks. arXiv preprint arXiv:1710.10903.
[9] Multiple authors (2021). Precision Medicine, AI, and the Future of Personalized Health Care. PMC. Retrieved from https://pmc.ncbi.nlm.nih.gov/articles/PMC7877825/
Author:

Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.