
Ankur Teredesai
CEO & Co-founder
CEO & Co-founder


The holy grail of health AI has always been personalization at scale: delivering the right intervention, to the right person, at the right time, across millions of users simultaneously. For years, this remained elusive. Traditional recommendation systems that worked beautifully for e-commerce and entertainment hit fundamental barriers when applied to health behavior change.
The breakthrough came not from scaling existing approaches, but from recognizing that health personalization requires a fundamentally different architecture—one that can model complex relationships between users, behaviors, interventions, and contextual factors in real-time. Enter Graph Neural Networks augmented with dynamic Knowledge Graphs.
Most health recommendation systems rely on collaborative filtering or content-based approaches adapted from e-commerce. But health behavior presents unique challenges that break these traditional models:
Sparse Interaction Data: Unlike e-commerce where users generate hundreds of implicit signals (clicks, views, purchases), health interventions generate sparse feedback. A user might interact with a health nudge only once per day, creating a data sparsity problem that collaborative filtering struggles to handle.
Context Criticality: The same intervention that motivates a user in the morning might be ignored or even counterproductive in the evening. Traditional matrix factorization approaches cannot capture these temporal and contextual dependencies effectively.
Cold Start Complexity: New users in health apps often have minimal interaction history but rich demographic and health data. Traditional systems struggle to leverage this heterogeneous information effectively.
Multi-Modal Integration: Health decisions are influenced by physiological data (heart rate, sleep), behavioral patterns (exercise history), environmental factors (weather, location), and social context [9]. Traditional recommender architectures aren’t designed for this level of multi-modal integration.
These limitations aren’t just theoretical—they represent the difference between a system that works in research settings and one that can drive sustained behavior change at population scale.
The solution emerged from recognizing that health personalization is fundamentally a graph problem. Users, interventions, behaviors, and contextual factors form a complex network of relationships that evolve continuously. Graph Neural Networks provide the perfect framework for modeling these relationships and propagating information across the network.
Dynamic Knowledge Graph Construction: Rather than static user-item matrices, the system constructs a heterogeneous knowledge graph where nodes represent users, interventions, behavioral markers, and contextual factors. Edges capture relationships like “user has characteristic,” “intervention targets behavior,” or “user interacted with intervention.”
The knowledge graph schema typically includes:
• User nodes: Demographics, health status, behavioral patterns
• Intervention nodes: Nudges, recommendations, educational content
• Behavioral marker nodes: Activity levels, health metrics, engagement patterns
• Contextual nodes: Time-of-day, weather conditions, social settings
• Relationship edges: Interactions, similarities, targeting rules, temporal associations
Attentive Graph Convolution: The GNN employs attention mechanisms to learn which relationships are most important for each prediction. Knowledge-aware attention specifically considers the semantic meaning of different edge types, allowing the model to weight relationships appropriately.
The attention mechanism uses relation-specific transformations [2]:
α(r,a,b) = softmax_b((W_r * e_b)^T * tanh(W_r * e_a + e_r))
Where W_r is a relation-specific transformation matrix, e_a and e_b are node embeddings, and e_r is the relation embedding.
Real-Time Adaptation: Unlike static models that require periodic retraining, the system continuously updates node embeddings as new interaction data arrives. This enables the model to adapt to changing user preferences and behaviors in near real-time.
Multi-Scale Personalization: The architecture supports personalization at multiple levels—from individual user preferences to population-level patterns—by aggregating information across different numbers of graph hops.
Handling Heterogeneous Data: Traditional GNNs assume homogeneous node types. Health applications require handling users, interventions, and contextual factors as fundamentally different entity types with different feature spaces. The solution involves type-specific embedding layers and attention mechanisms.
Temporal Dynamics: User health states and preferences evolve continuously. The architecture addresses this through time-aware embeddings and decay mechanisms that reduce the influence of outdated interactions.
Scalability Engineering: Population-scale deployment requires processing millions of nodes and edges efficiently. Key optimizations include:
• Parallel batch processing with automatic retry mechanisms
• Distributed graph storage with locality-aware partitioning
• Efficient sampling strategies for large neighborhoods
• Incremental embedding updates to avoid full recomputation
Privacy-Preserving Design: Health data requires advanced privacy protection. The system operates on pseudonymized identifiers and can be deployed in air-gapped environments with no external data transfer.
Fault Tolerance: Clinical applications demand high reliability. The architecture includes automated retry mechanisms, batch-level failure recovery, and comprehensive monitoring across graph construction, model inference, and recommendation delivery pipelines.
Regulatory Compliance: Healthcare deployments require audit trails and explainability. The attention mechanisms provide natural interpretation paths by highlighting which relationships contributed most to each recommendation.
Academic literature provides concrete evidence of GNN effectiveness in health applications. Research published in KDD 2024 documents a production system serving over 1 million users daily with the following validated results [1]:
Model Performance: Precision@3 of 0.0501 for predicting user interactions with health interventions, with stable performance over 4-month production deployment (standard deviation < 0.007 across daily model updates) [1].
Behavioral Impact: Controlled studies demonstrate statistically significant improvements in health behaviors [1]:
• 6.17% increase in daily physical activity (p = 3.09 × 10^-4)
• 7.61% increase in weekly exercise duration (p = 1.16 × 10^-2)
• 13.1% engagement rate compared to 4% baseline for traditional approaches
Scalability Validation: Linear scaling demonstrated from 300,000 to 19 billion candidate user-intervention pairs, with strong correlation (R² = 0.9997) between dataset size and processing time on commodity hardware [1].
System Reliability: 18+ months of continuous operation with automated daily model updates completing in 90-150 minutes, demonstrating production-grade stability [1].
Dynamic Graph Updates: Traditional GNN implementations assume static graphs. Health applications require continuous graph evolution as users’ health states change. The solution involves efficient incremental embedding updates and change propagation algorithms.
Multi-Modal Feature Integration: Combining physiological sensor data, demographic information, and behavioral patterns requires careful feature engineering and attention mechanisms that can weight different modalities appropriately.
Real-Time Inference: Generating personalized recommendations for millions of users daily requires optimized inference pipelines. Key innovations include pre-computed user embeddings, efficient candidate generation, and distributed serving architectures.
Cold Start with Rich Context: New users lack interaction history but often have rich demographic and health data. The GNN architecture solves this by propagating information from similar users through the graph, enabling immediate personalization based on shared characteristics and goals.
The success of GNN-based health personalization has catalyzed broader industry adoption. Epic’s 2025 launch of AI agents for personalized medicine signals enterprise healthcare systems are moving toward graph-based architectures for clinical decision support [3]. With 65% of US hospitals already using predictive models [4], the foundation for graph-based health AI is accelerating.
Consumer health platforms are increasingly adopting similar approaches. Major wearable manufacturers are integrating graph-based models for activity recommendations, while chronic disease management apps use knowledge graphs to model complex comorbidity relationships [5].
Federated Graph Learning: Multiple healthcare organizations can collaboratively train models without sharing patient data, using federated learning techniques adapted for graph neural networks.
Multimodal Graph Fusion: Integration of speech pattern analysis, social media sentiment, and biometric data into unified graph representations for more comprehensive health modeling.
Causal Graph Discovery: Moving beyond correlation to identify causal relationships in health behavior networks, enabling more effective intervention design.
Temporal Graph Networks: Advanced architectures that explicitly model how health relationships evolve over time, improving long-term outcome prediction.
The convergence of proven GNN architectures, scalable graph processing infrastructure, and validated health applications creates unprecedented opportunities for technical innovation in healthcare AI. For technical leaders, the question isn’t whether to adopt graph-based approaches—it’s how quickly you can adapt them to your specific health domain.
Enterprise Healthcare AI Deployments
Epic’s AI Agent Architecture: Healthcare’s largest EHR provider is deploying AI agents for personalized medicine at scale [3], with 65% of US hospitals already using predictive models [4]. The architecture emphasizes real-time treatment adjustment based on continuous monitoring, suggesting graph-based approaches for modeling patient-provider-treatment relationships.
Clinical Decision Support Systems: Mount Sinai’s deployment of AI delirium prediction represents the first AI model demonstrating real-world clinical benefits beyond laboratory performance [6]. The system integrates multiple data streams (vitals, medications, lab results) in ways that suggest knowledge graph architectures for relationship modeling.
Wearable Data Integration: Major platforms (Oura, WHOOP, Apple) are competing on AI-powered behavioral insights that require processing multimodal sensor streams. Technical requirements include:
• Real-time biometric data processing (heart rate variability, sleep stages, activity patterns)
• Context-aware recommendation engines that adapt to circadian rhythms
• Privacy-preserving on-device inference for sensitive health data
Conversational Health AI: The emergence of LLM-powered health coaches (Thrive AI Health, various startups) creates new technical challenges:
• Integrating structured health data with unstructured conversation
• Maintaining conversation context across multiple health domains
• Ensuring medical accuracy while enabling natural language interaction
Google Health AI Initiatives: The 2025 AI for Health cohort showcases cutting-edge technical approaches [7]:
• Facial Expression Analysis: Computer vision models for mental health assessment requiring real-time video processing and privacy protection
• Smartphone Health Screening: 2-minute health assessments using device sensors for early diagnosis, demonstrating edge AI capabilities
• Multimodal Health Monitoring: Integration of audio, visual, and sensor data for comprehensive health state assessment
Federated Learning in Healthcare: Growing adoption of privacy-preserving collaborative learning where multiple healthcare organizations train shared models without data centralization. Technical challenges include:
• Handling non-IID data distributions across healthcare systems
• Maintaining model quality while preserving privacy
• Coordinating updates across heterogeneous infrastructure
Health Data Standards Integration: FHIR (Fast Healthcare Interoperability Resources) adoption is accelerating, creating opportunities for standardized health knowledge graph schemas. Technical implications include:
• Standardized data models for cross-system interoperability
• Graph database optimizations for FHIR resource relationships
• Real-time data synchronization across healthcare systems
Privacy-Preserving Technologies: Advanced cryptographic techniques becoming practical for health AI:
• Homomorphic Encryption: Computation on encrypted health data
• Secure Multi-Party Computation: Collaborative analysis without data sharing
• Differential Privacy: Mathematical privacy guarantees for population health studies
Scalability Comparisons: Industry benchmarks emerging for health AI systems:
• Latency requirements: <100ms for real-time recommendations
• Throughput targets: Processing millions of users daily
• Accuracy baselines: Precision@K metrics for health intervention recommendations
• Resource efficiency: Cost per user per day for cloud deployments
Model Architecture Evolution: Technical trends in health AI architectures:
• Migration from collaborative filtering to graph neural networks
• Adoption of transformer architectures for sequential health data
• Integration of causal inference techniques for intervention design
• Multi-task learning for simultaneous health outcome prediction
This technical landscape represents the convergence of advanced AI research with practical healthcare deployment requirements. For engineering teams, success requires balancing algorithmic sophistication with regulatory compliance, privacy protection, and clinical safety standards.
References
[1] Chiam, J., Lim, A., & Teredesai, A. (2024). NudgeRank: Digital Algorithmic Nudging for Personalized Health. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24).
[2] Wang, X., He, X., Cao, Y., Liu, M., & Chua, T. S. (2019). KGAT: Knowledge graph attention network for recommendation. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 950-958.
[3] Reich, V. (2025). 2025: AI enhances personalized care; caregiver experience in spotlight. Healthcare IT News. Retrieved from https://www.healthcareitnews.com/news/2025-ai-enhances-personalized-care-caregiver-experience-spotlight
[4] Multiple authors (2025). Current Use of AI and Predictive Models in US Hospitals. Health Affairs, 44(1). https://doi.org/10.1377/hlthaff.2024.00842
[5] Breen, J. (2024). AI Health Coaches Unlock Personalized Insights. Fitt Insider. Retrieved from https://insider.fitt.co/ai-health-coaches-unlock-personalized-insights/
[6] Friedman, C., et al. (2025). AI Model Improves Delirium Prediction. JAMA Network Open. Mount Sinai Press Release: https://www.mountsinai.org/about/newsroom/2025/ai-model-improves-delirium-prediction
[7] Google Team (2025). Google’s 2025 Growth Academy: AI for Health cohort. Google Blog. Retrieved from https://blog.google/outreach-initiatives/entrepreneurs/growth-academy-ai-health-2025/
[8] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., & Bengio, Y. (2017). Graph attention networks. arXiv preprint arXiv:1710.10903.
[9] Multiple authors (2021). Precision Medicine, AI, and the Future of Personalized Health Care. PMC. Retrieved from https://pmc.ncbi.nlm.nih.gov/articles/PMC7877825/

Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.

The hidden economics that are killing your device business
“Isn’t high device churn actually good for business? More churn means more sales, right?”
This question comes up in every executive meeting when discussing wearable retention strategies. On the surface, the logic seems sound: if users abandon their devices after 6 months, they’ll need to buy new ones, creating recurring hardware revenue. But this thinking reveals a fundamental misunderstanding of wearable economics that’s quietly destroying value across the industry.
The math tells a different story—one where high churn is actually a symptom of a broken business model, not a feature.
The first crack in the “churn is good” theory appears when you examine customer acquisition costs. Recent data show that mobile app customer acquisition costs have surged 222% over the past decade, rising from $19 to $29 per user [1]. For fitness-focused applications, the numbers are even more sobering: acquiring an in-app buyer costs $74.68, while subscription customers cost $64.27 to acquire [2].
For fitness centers, the average customer acquisition cost sits at $118 per client [3]. When you extrapolate these figures to wearable devices—which require similar marketing investments, retail partnerships, and brand building—the true cost of replacement becomes clear.
Consider this: if you’re spending $50-150 to acquire each wearable customer (a conservative estimate based on industry benchmarks), and they abandon the device after 6 months, you’re in a constant battle to replace lost customers rather than building sustainable value from existing ones.
Recent market data reveals telling patterns about device adoption and abandonment across key markets:
India: The Low-Cost Trap India represents approximately 8.5% of population penetration (119 million units among ~1.4 billion people) but leads globally in total shipment volumes [4,5]. The market experienced 34% growth in 2023, reaching 134.2 million units [5]. However, industry analysis reveals that “watch lifecycles are as short as 6 months” due to “lackluster tracking performance leading to high abandonment” [6]. The smartwatch market actually declined 4.5% in 2024, partly due to an “influx of low-cost options” that created elevated inventory levels [7].
Singapore: The Engagement Success Story Singapore demonstrates the alternative model. With 44.1% fitness tracker ownership among older adults, driven by the National Steps Challenge providing free devices [8], the country shows how government partnership and engagement-focused strategies can drive sustained usage rather than churn.
UAE: The Premium Opportunity The UAE represents 30.2% of the Middle East & Africa wearable market, with 15% of the population using fitness trackers in 2023 [9]. The market shows healthy 14.3% CAGR growth, suggesting that focusing on engagement rather than replacement drives sustainable expansion.
Three approaches, three outcomes
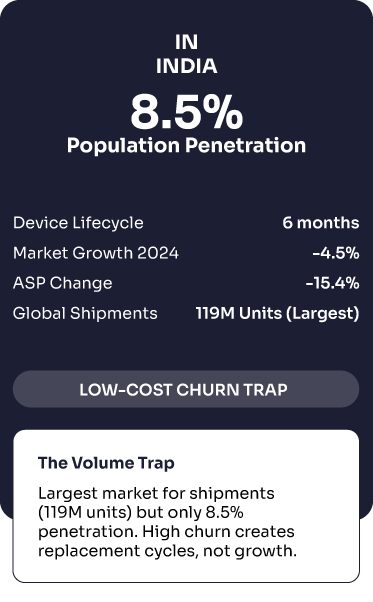


Largest market for shipments (119M units) but only 8.5% penetration. High churn creates replacement cycles, not growth
Government partnership drives sustained usage through free devices + behavior change programs.
Lower adoption but healthy growth focused on advanced features and targeted use cases.
The fundamental issue lies in the economics of one-time hardware sales versus recurring subscription revenue. Modern business theory emphasizes that Customer Lifetime Value (LTV) should be at least 3x higher than Customer Acquisition Cost (CAC) for a sustainable business model [10].
Hardware-Only Model:
• CAC: $50-150 per customer
• Average selling price: $87 per device (Fitbit example) [11]
• If customer churns after 6 months: LTV = $87
• LTV:CAC ratio = 0.58:1 to 1.74:1 (unsustainable)
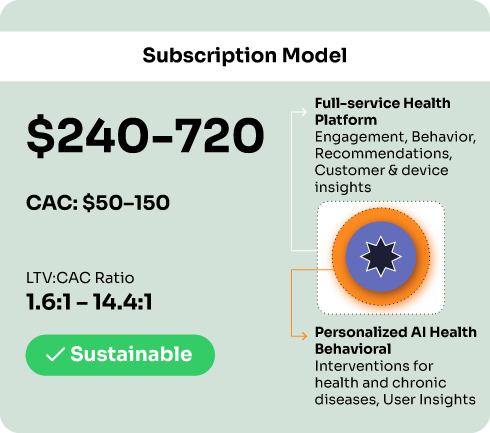
Subscription Model:
• CAC: $50-150 per customer
• Monthly subscription: $10-30
• Average customer lifetime: 24+ months with engagement
• LTV = $240-720
• LTV:CAC ratio = 1.6:1 to 14.4:1 (sustainable to excellent)
Why the “churn is good” business model destroys value
Industry Benchmark: 3:1 LTV:CAC ratio for sustainable growth


Each churned customer requires spending another $50-150 to replace while only generating $87 in return.

Higher LTV enables aggressive customer acquisition while maintaining profitability margins

Value destroyed by focusing on hardware sales instead of building subscription venue

Companies with 3:1+ can outspend competitors on marketing and stay profitable
Fitbit’s trajectory provides the most compelling evidence against the “churn is good” thesis. The company’s valuation peaked at $9.7 billion in 2015, crashed to $1.4 billion in 2017, and was eventually acquired by Google for $2.1 billion [11]—representing a 78% value destruction.
Key metrics from Fitbit’s decline:
• Active users: 38.5 million in 2023 (down 3.75%) [11]
• Estimated unit sales: 6.6 million in 2023 [11]
• Financial performance: Unprofitable since 2015, with $320 million loss in 2019 alone
The company sold over 100 million devices but retained only 28 million users—massive churn that prevented the transition to sustainable subscription revenue [12].
Without direct access to internal CAC data from major wearable manufacturers, several market indicators reveal the true cost of high churn:
Marketing Spend Escalation Connected fitness companies like Peloton saw sales and marketing expenses “more than doubled to account for 35.3% of total revenue” as they fought customer acquisition battles [13]. This level of marketing spend is unsustainable when customers don’t generate recurring value.
Valuation Compression The wearables industry has experienced widespread valuation compression. Beyond Fitbit’s decline, the broader fitness tracker market shows average selling prices dropping 15.4% in key markets like India, from $25.0 to $21.2 [14].
Market Maturity Signals IDC reports that major markets like the US and India, along with key device categories, are “approaching maturity,” with growth slowing to 4.1% in 2025 [15]. This suggests the easy growth from constant customer replacement is ending.
Companies that solve retention enjoy compounding advantages:
Data Value Appreciation Engaged users generate continuous data streams that improve AI algorithms, enable personalized coaching, and create network effects. Abandoned devices provide zero ongoing data value.
Ecosystem Revenue Opportunities Apple’s approach demonstrates the alternative model: services revenue from engaged users reached $8 billion annually. Accessories, apps, and subscriptions only work with sustained device usage.
B2B Partnership Leverage Corporate wellness programs and insurance partnerships pay for proven health outcomes, not device sales. These relationships require demonstrated user engagement and measurable health improvements.
The evidence points to a clear conclusion: high wearable churn isn’t a renewable revenue feature—it’s a value destruction mechanism that indicates fundamental product-market fit problems.
For Executives: Track engagement metrics alongside sales numbers. Monitor customer lifetime beyond initial purchase. Measure recurring revenue from services, subscriptions, and partnerships.
For Product Teams: Focus on behavior change outcomes rather than feature proliferation. Build AI-powered coaching that adapts to individual users. Create sustainable habits, not short-term motivation spikes.
For Investors: Look for companies building platform businesses around sustained engagement rather than hardware replacement cycles. Evaluate LTV:CAC ratios and recurring revenue streams as primary value indicators.
The companies that recognize this shift—from hardware churn to engagement sustainability—will capture the majority of the value as the wearables market matures. Those clinging to the “churn is good” thesis will find themselves in an increasingly expensive game of customer replacement, with diminishing returns and compressed valuations.
The choice is clear: build for retention, or watch your competition capture the real value in wearable technology.
References:
[1] Business of Apps. (2025). App User Acquisition Costs (2025). https://www.businessofapps.com/marketplace/user-acquisition/research/user-acquisition-costs/
[2] Appetiser. (2024). Customer Acquisition Cost for Apps: What to Expect in 2024. https://appetiser.com.au/blog/customer-acquisition-cost-for-apps/
[3] WellnessLiving. (2024). Your Ultimate Guide to Customer Acquisition Cost. https://www.wellnessliving.com/blog/ultimate-guide-customer-acquisition-cost/
[4] IDC. (2024). India’s Wearable Device Market Analysis. Various reports indicate approximately 8.5% population penetration despite high shipment volumes.
[5] IDC. (2024). India’s Wearable Device Market Grew 34% in 2023 to 134 Million Units. https://my.idc.com/getdoc.jsp?containerId=prAP51880624
[6] Canalys. Time for change in India’s smart wearable market. https://canalys.com/insights/time-change-india-smart-wearable-market
[7] IDC. (2025). Wearable Devices Market Insights. https://www.idc.com/promo/wearablevendor/
[8] JMIR Aging. (2025). Exploring Smart Health Wearable Adoption Among Singaporean Older Adults. https://aging.jmir.org/2025/1/e69008
[9] Global Growth Insights. (2025). Smart Wearables Market Size, Share | Industry Statistics, 2033. https://www.globalgrowthinsights.com/market-reports/smart-wearables-market-110856
[10] ChartMogul. Customer Lifetime Value (LTV). https://chartmogul.com/saas-metrics/ltv/
[11] Business of Apps. (2025). Fitbit Revenue and Usage Statistics (2025). https://www.businessofapps.com/data/fitbit-statistics/
[12] Coolest Gadgets. Fitbit Customer Base Analysis. Historical acquisition data from industry reports.
[13] Tribe.fitness. The Rising Cost of Customer Acquisition in Connected Fitness. https://www.tribe.fitness/blog/the-rising-cost-of-customer-acquisition-in-connected-fitness
[14] IDC India. India’s Wearable Device Market Analysis 2023-2024.
[15] IDC. (2025). Global Wearables Market Outlook 2025. https://www.idc.com/promo/wearablevendor/
Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.
Why the biggest opportunity in healthcare isn’t the next genomic breakthrough—it’s sitting in our pockets
Here’s an uncomfortable truth that should reshape every healthcare investment decision: we’re systematically investing in the wrong 20%.
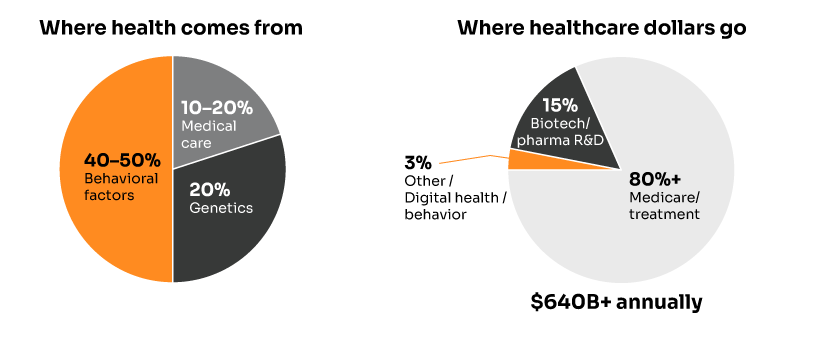
While the healthcare industry pours $640+ billion annually into medical care and billions more into genomic research, mounting evidence reveals that medical interventions account for just 10-20% of health outcomes. Meanwhile, behavioral factors—which research consistently shows drive 40-50% of health outcomes—receive a fraction of the investment and attention.
This isn’t just an academic curiosity. It’s a massive market inefficiency that 2025 is finally beginning to correct.
The data is overwhelming, even if the exact percentages vary by study. The seminal McGinnis & Foege research in JAMA identified behavioral factors as the leading “actual causes of death” in the United States. Subsequent analyses consistently confirm the hierarchy:
• 40-50% Behavioral factors (diet, exercise, substance use, medication adherence)
• 20% Social and environmental factors (income, education, housing, air quality)
• 20% Genetics (hereditary predispositions, family history)
• 10-20% Medical care (hospitals, drugs, procedures, devices)
Yet our healthcare spending is almost perfectly inverted. We dedicate massive resources to the 10-20% while largely ignoring the 40-50%.
The American Action Forum puts it bluntly: “95 percent of U.S. health expenditures go toward medical care,” while most experts agree that “medical services have a limited impact on health and well-being.”
This represents the largest ROI opportunity in healthcare—and 2025 is the year it’s finally being seized at scale.
Three converging forces are creating an unprecedented opportunity for behavioral intervention:
AI Technology Maturation: Graph Neural Networks, Large Language Models, and real-time personalization have evolved from research curiosities to production-ready systems capable of delivering hyper-personalized behavior change at population scale.
Proven Business Model: Early implementations are demonstrating concrete ROI. Healthcare organizations using AI personalization are achieving 5-10% cost savings—a massive impact in an industry where margins are measured in single digits.
Market Validation: 2025 marks the transition from experimental pilots to mainstream deployment, with major industry players committing resources that signal this is no longer a “nice to have” but a competitive necessity.
The evidence for behavioral AI’s transformative potential isn’t theoretical—it’s happening right now across multiple fronts.
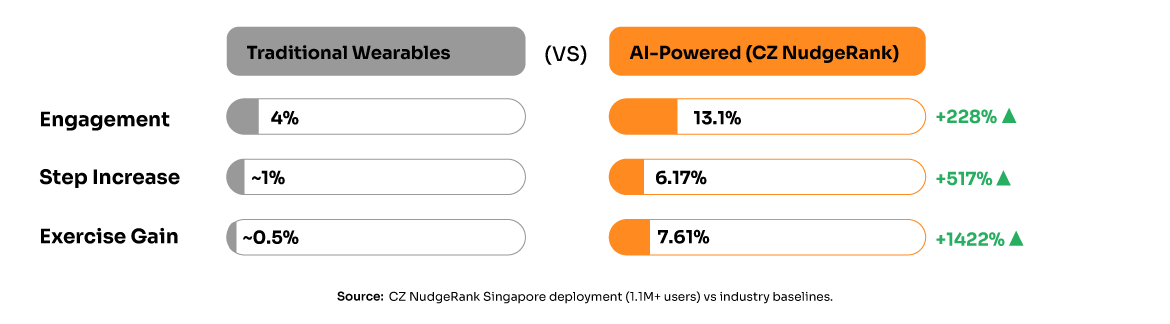
The most compelling proof comes from Singapore’s deployment of NudgeRank™, an AI-powered behavioral intervention system serving over 1.1 million citizens daily. The results from their 12-week study are remarkable:
• 6.17% increase in daily steps among intervention group
• 7.61% increase in weekly exercise minutes
• 13.1% nudge open rate compared to 4% baseline
• 6:1 positive-to-negative rating ratio for AI-generated nudges
This isn’t a small pilot—it’s population-scale validation that AI-driven behavioral interventions work when properly implemented.
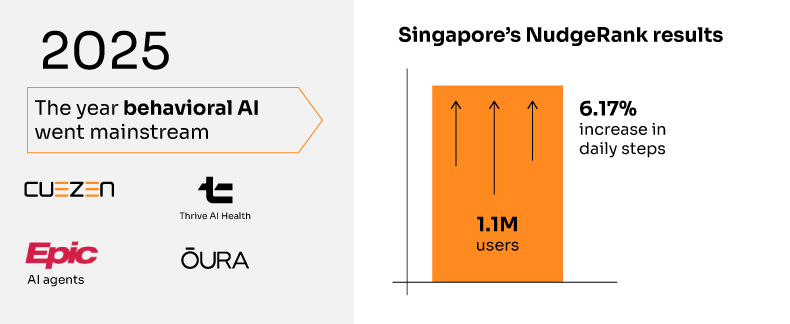
Major AI Health Partnerships: The OpenAI-Thrive Global partnership creating Thrive AI Health represents billions in backing for hyper-personalized health coaching. Their focus on chronic disease management through behavioral change directly targets the highest-cost, highest-impact health challenges.
Healthcare System Adoption: Epic’s 2025 launch of AI agents for personalized medicine signals that the largest EHR provider sees AI-powered personalization as core infrastructure, not optional enhancement. With 65% of US hospitals already using predictive models, the foundation for behavioral AI deployment is accelerating.
Consumer Platform Evolution: Oura’s AI Advisor, WHOOP’s AI coach, and Apple’s expanding health capabilities show consumer platforms are competing on AI-powered behavioral insights. These aren’t research projects—they’re core product strategies backed by billions in market capitalization.
Clinical Validation: Mount Sinai’s deployment of AI delirium prediction—the first AI model to demonstrate real-world clinical benefits beyond laboratory performance—proves that AI can successfully transition from research to patient care. Meanwhile, Penn Medicine’s Nudge Unit achieved dramatic results like increasing generic prescribing rates from 75.3% to 98.4% through behavioral interventions.
Emerging Innovation: Google’s 2025 AI for Health cohort showcases cutting-edge applications like BLUESKEYE AI’s facial expression analysis for early diagnosis and YOUTH Health Tech’s 2-minute smartphone health screening. These represent the next wave of behavioral health innovation moving toward clinical deployment.
Market Segmentation Insights: McKinsey’s 2025 wellness survey identified five distinct consumer segments, with “maximalist optimizers” representing 25% of consumers but 40% of spending—precisely the market most receptive to AI-powered behavioral interventions.
While healthcare systems debate implementation, the opportunity cost compounds. Every day, behavioral risk factors drive preventable deaths and expensive emergency interventions. The leading “actual causes of death”—tobacco use, poor diet, physical inactivity—remain largely unaddressed by systematic behavioral intervention at scale.
Organizations that delay behavioral AI adoption aren’t just missing efficiency gains—they’re ceding competitive advantage to systems that can demonstrate better outcomes at lower costs.
For healthcare leaders, the question isn’t whether to invest in behavioral AI—it’s how quickly you can deploy it effectively. The convergence of proven technology, demonstrated ROI, and market demand creates a narrow window for competitive advantage.
For Health Systems: Behavioral AI offers the rare opportunity to improve outcomes while reducing costs. Early adopters can differentiate on both patient satisfaction and economic performance.
For Investors: The Singapore validation and industry adoption signals suggest we’re at the base of the adoption curve for a massive market opportunity. The companies that solve behavioral intervention at scale will capture disproportionate value.
For Policymakers: Behavioral AI represents the most promising path to bend the healthcare cost curve while improving population health outcomes—exactly what public health policy has sought for decades.
The research is clear, the technology is ready, and the early results are compelling. The question is no longer whether behavioral factors drive health outcomes—it’s whether your organization will be among the first to systematically address them at scale.
The $640 billion misdirection is finally being corrected. The only question is whether you’ll be leading the correction or following it.
References:
• McGinnis & Foege, “Actual Causes of Death in the United States,” JAMA (1993)
• American Action Forum, “Understanding the Social Determinants of Health” (2018)
• Chiam et al., “NudgeRank: Digital Algorithmic Nudging for Personalized Health,” KDD (2024)
• Multiple healthcare industry analyses and reports (2024-2025)
Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.
In our previous post, we compared ID-Based and ID-Free recommendation models and found that ID-Free approaches generally produced higher-quality recommendations for personalized digital health nudging. In this post, we examine how ID-Free models behave under different conditions, focusing on three core questions:
1. How do ID-Free models scale as training data increases?
2. What trade-offs exist between recommendation quality, training time, and computational resources?
3. How much do semantic embeddings contribute, evaluated by comparing ID-Free and ID-Based versions of the same models?
To address these questions, we benchmarked several recommendation architectures powered by ID-Free semantic embeddings across varying training data sizes and conducted an ablation study contrasting each model’s ID-Free and ID-Based implementations.
We used the same proprietary digital health recommendation dataset as in our previous post. It consists of user–nudge interactions, enriched with metadata for both users (e.g., demographics, health conditions, aggregated tracker data) and nudges (e.g., content text, categories, target behaviors).
For all experiments, we maintained consistent validation and test sets, each covering one week of interaction data. The training data window was varied across 1, 2, 4, and 10 weeks to observe model behavior at different data volumes. Table 1 summarizes the dataset statistics for these splits.
| Split | # Users | # Nudges[1] | # Interactions |
|---|---|---|---|
| Train (1 week) | 2,334 | 56 | 3,158 |
| Train (2 weeks) | 4,176 | 56 | 6534 |
| Train (4 weeks) | 7,833 | 59 | 14,075 |
| Train (10 weeks) | 15,544 | 59 | 35,723 |
| Validation (1 week) | 2,285 | 70 | 3088 |
| Test (1 week) | 2,290 | 69 | 3,082 |
[1]Additional nudges were introduced in the production system during the validation and test periods, resulting in higher counts compared to the training splits.
Table 1: Dataset Statistics for train (1–10 weeks), validation, and test splits.
Model performance was evaluated using standard top-K recommendation metrics at K = 3:
• NDCG@3 (Normalized Discounted Cumulative Gain)
• Precision@3
• Recall@3
• MAP (Mean Average Precision)
The models we tested included:
• ID-Free Models: BPR, NeuMF, SimpleX, and SASRec, which leverage semantic embeddings derived from user and nudge metadata. These models span approaches from collaborative filtering to sequential modeling (see our previous post for details).
• ID-Based Counterparts: To isolate the impact of semantic embeddings, we implemented ID-based versions of the same models trained on discrete user and nudge IDs.
• Baselines: Two simple non-personalized models, Random and Popular, as benchmarks.
All models were trained using the same procedures and configurations described previously:
• Hyperparameter Tuning: Optimal hyperparameters for each model were selected by maximizing NDCG@3 on the validation set.
• Training and Evaluation: Models were trained until convergence, with early stopping to prevent overfitting. Final performance was measured on the held-out test set.
• Training Time: Training durations were recorded to assess computational efficiency across different training data sizes.
Understanding how recommendation models scale with varying amounts of training data is critical for real-world deployment, especially in dynamic environments like digital health, where user behavior and nudge content evolve rapidly. Models must perform adequately with limited historical interactions (e.g., for new users or nudges) while leveraging additional data as it becomes available.
We evaluated four ID-Free models — BPR, NeuMF, SimpleX, and SASRec — together with baselines across training windows from 1 to 10 weeks. Validation and test sets were held constant to isolate the effect of training volume. Our analysis examines both recommendation quality and training time, highlighting trade-offs between performance and computational cost.
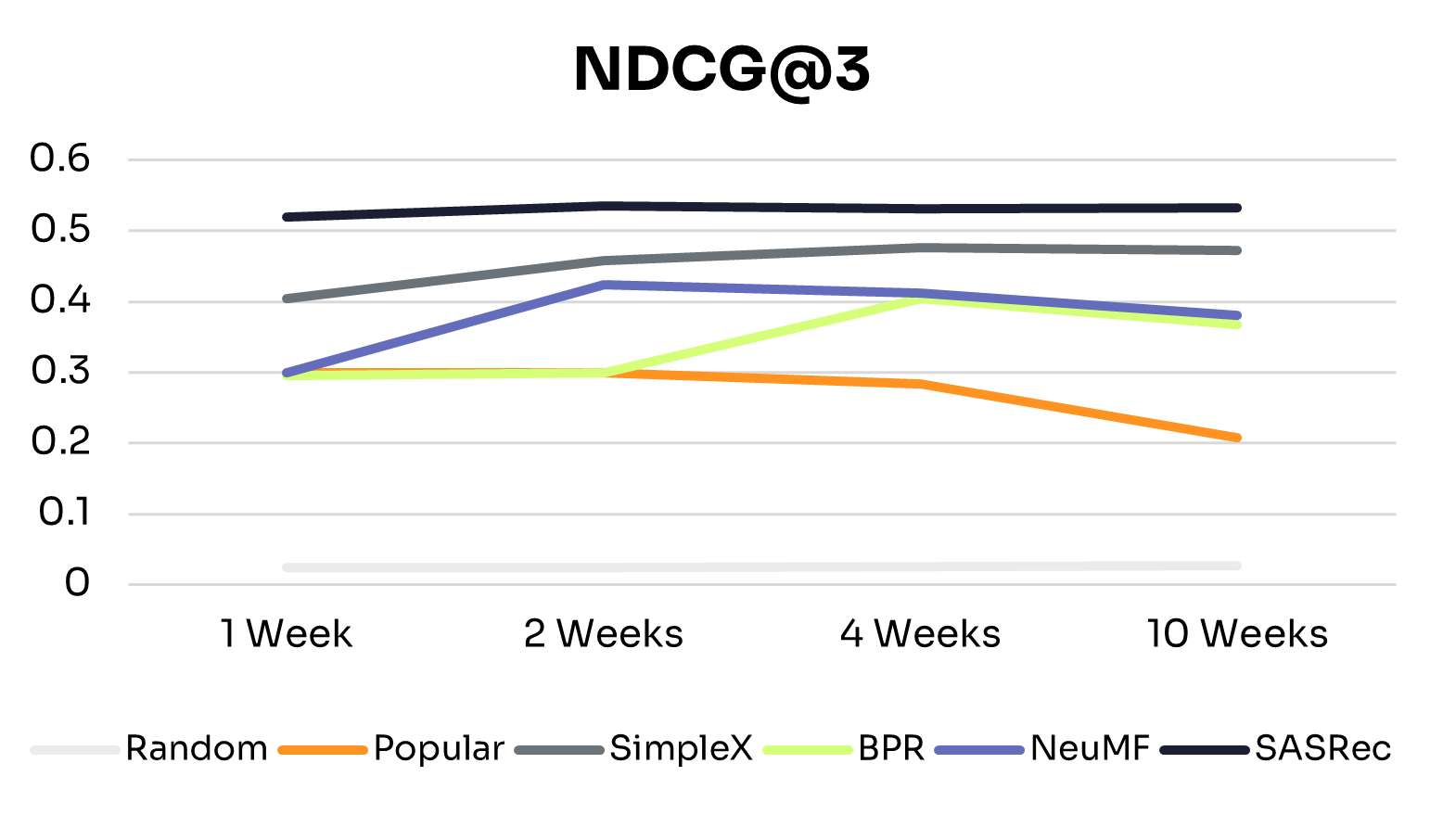
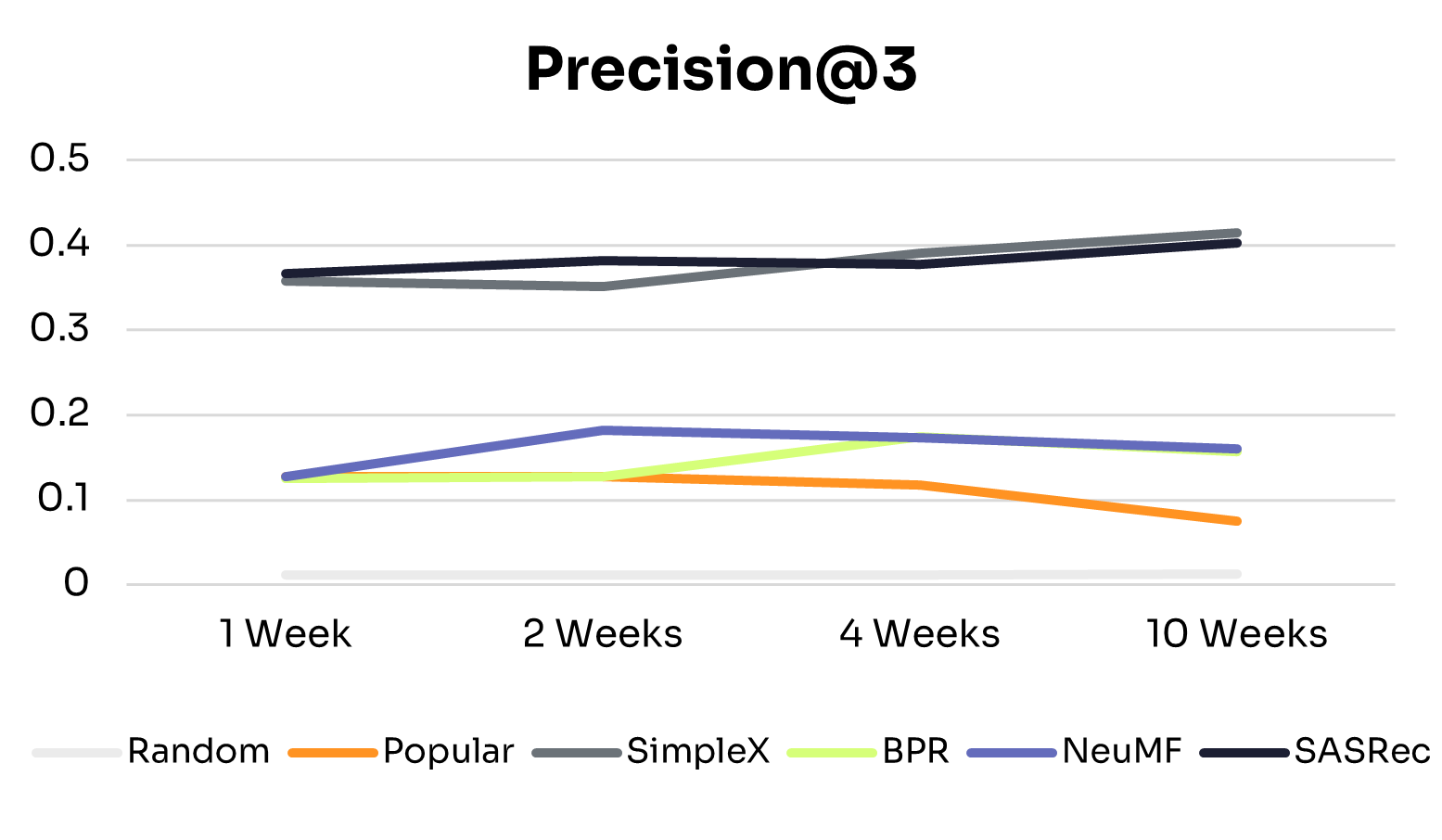
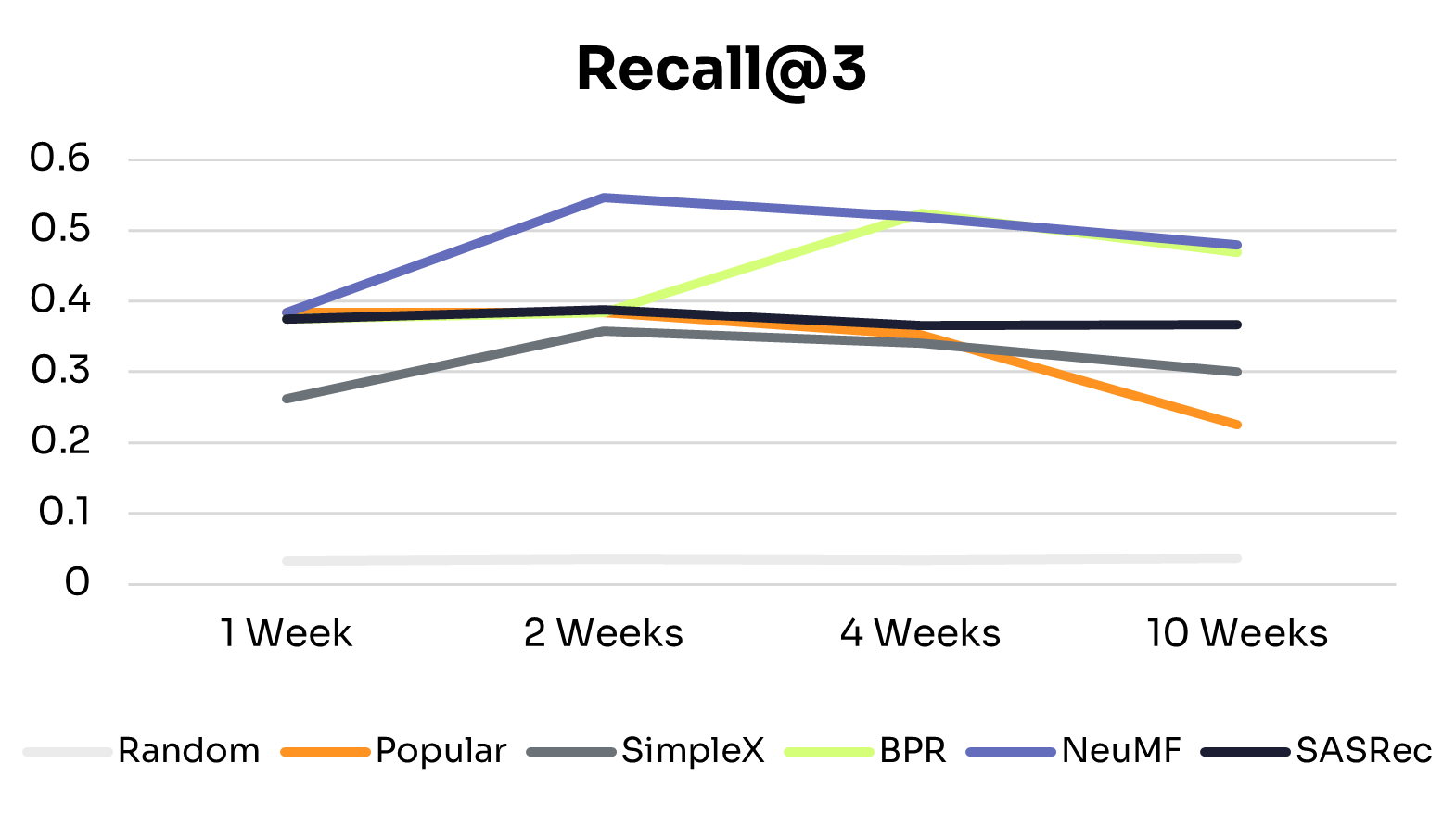
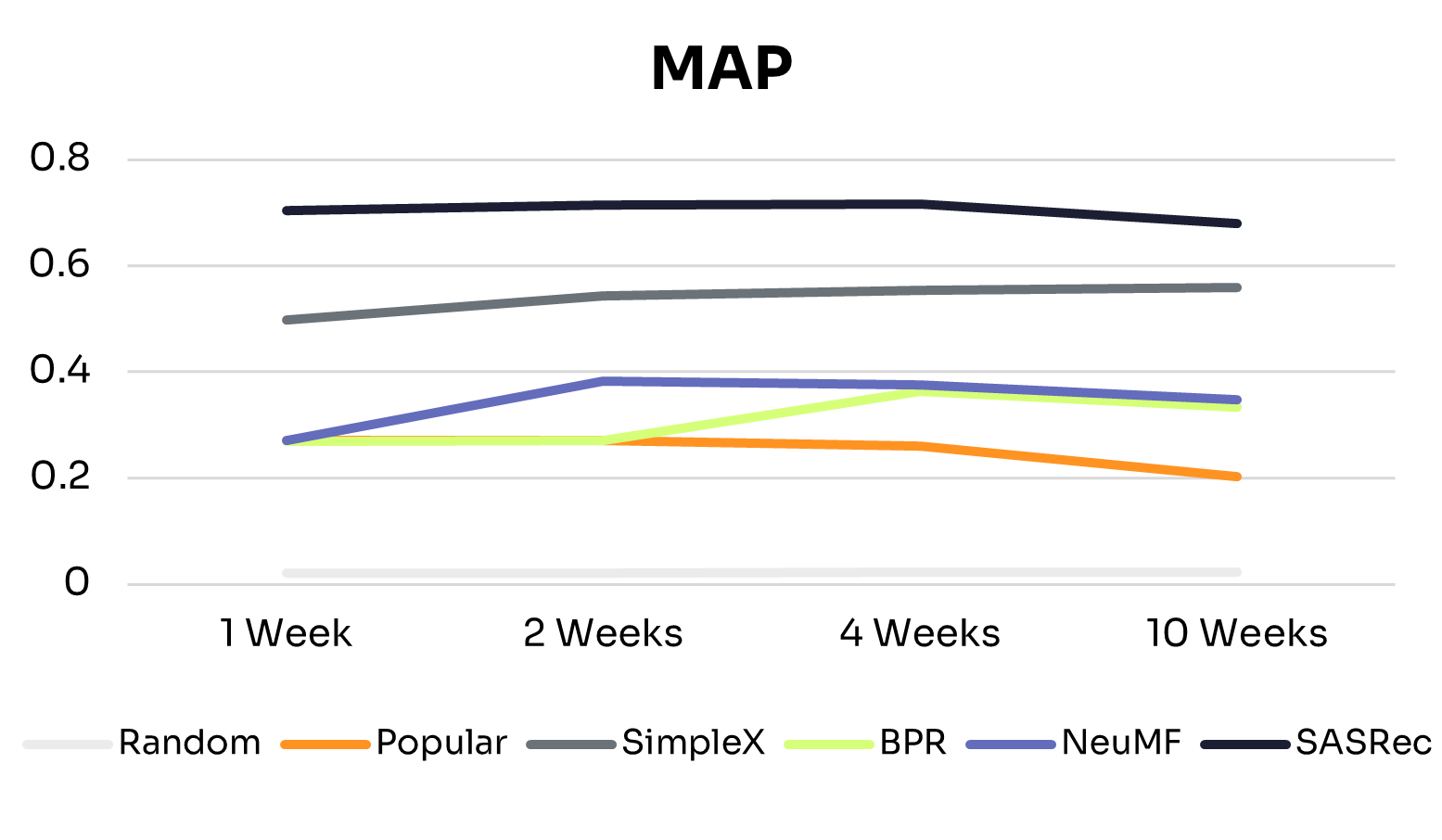
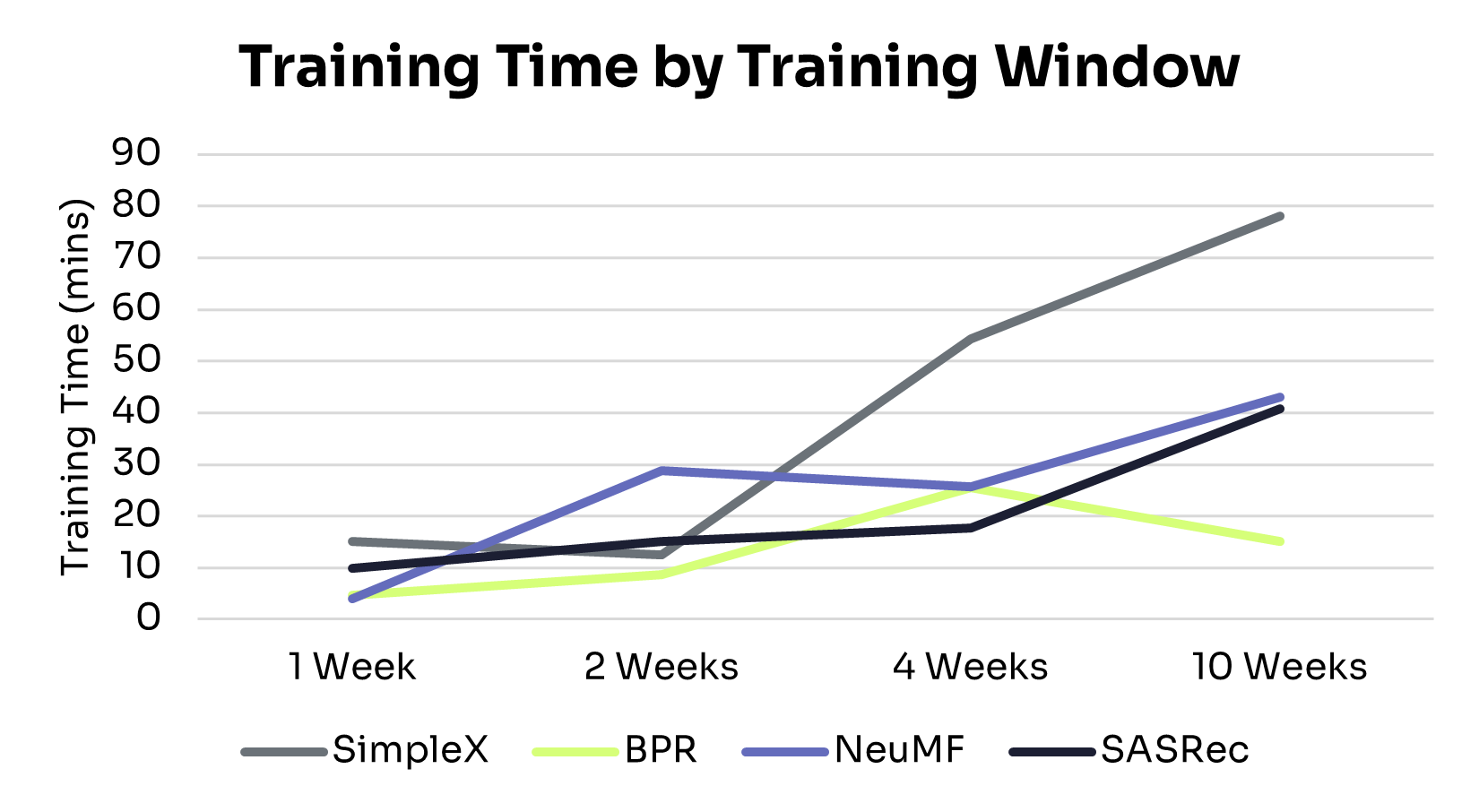
Figures 1 and 2 show how recommendation quality and training time vary across training windows.
As expected, across all training windows, ID-Free models consistently outperformed the Random baseline. The Popular baseline performed better with small training windows but declined as training data increased, likely due to shifts in nudge popularity. This highlights the advantage of learned personalized models over static baselines.
All ID-Free models improved across most metrics as training data increased from 1 to 4 weeks, suggesting they could learn richer patterns from additional interactions. Beyond 4 weeks, performance plateaued or declined slightly, indicating diminishing returns due to limited model capacity to exploit additional data or noise from older interactions.
• BPR: The simplest model in the group, BPR peaked at 4 weeks and remained the lowest-performing model, suggesting that its pairwise ranking objective and limited capacity constrain generalization to larger, more diverse datasets.
• NeuMF: Peaked at 2 weeks, with slight declines at 4 and 10 weeks. Its hybrid architecture captures short-term patterns effectively, but without explicit temporal modeling, older interactions can introduce noise in longer histories.
• SimpleX: Showed consistent improvements from 1 to 10 weeks on NDCG@3, Precision@3, and MAP, with Recall@3 peaking at 2 weeks before tapering. This suggests that its sequence-aware architecture can extract long-term patterns while mitigating noise from older interactions.
• SASRec: The most stable and high-performing model across all training windows, performing well even with 1 week of data and maintaining or slightly improving performance up to 10 weeks. This reflects its ability to capture temporal dependencies effectively through sequential modeling and attention mechanisms.
These differences align with each model’s architecture: SimpleX and SASRec incorporate historical interactions directly into their scoring, whereas BPR and NeuMF do not. This structural difference likely explains why SimpleX and SASRec scale more effectively as data increases.
Training efficiency varied considerably across models as data volume increased. Here’s how they compare, from the most to least efficient:
• BPR: Minimal computational overhead, with training time under 30 minutes across all data sizes. Its limited capacity, however, constrains recommendation quality in larger or more complex datasets.
• SASRec: Balances performance and efficiency. Training time increased near-linearly with data volume, delivering strong recommendations without excessive cost.
• NeuMF: Training time grew more steeply than BPR and SASRec, with diminishing returns on performance. This makes it more suitable for short interaction windows or smaller datasets.
• SimpleX: Achieved strong performance gains but at the highest computational cost, with runtime rising sharply and surpassing all other models at the 10-week mark. This makes it best suited for settings with larger datasets and less constrained compute resources.
These trade-offs highlight the need to balance model performance and computational cost when selecting an architecture for production deployment.
The previous section examined how ID-Free models scale with training data, but it did not isolate how much of their performance comes from semantic embeddings versus the model architecture itself. To address this, we conducted an ablation study comparing each model’s ID-Free variant (using semantic metadata) with its ID-Based counterpart (trained on discrete user and nudge IDs). This head-to-head setup directly measures the contribution of semantic embeddings across architectures.
Since most models performed best at the 4-week training window, we used this setting as the basis for the ablation.
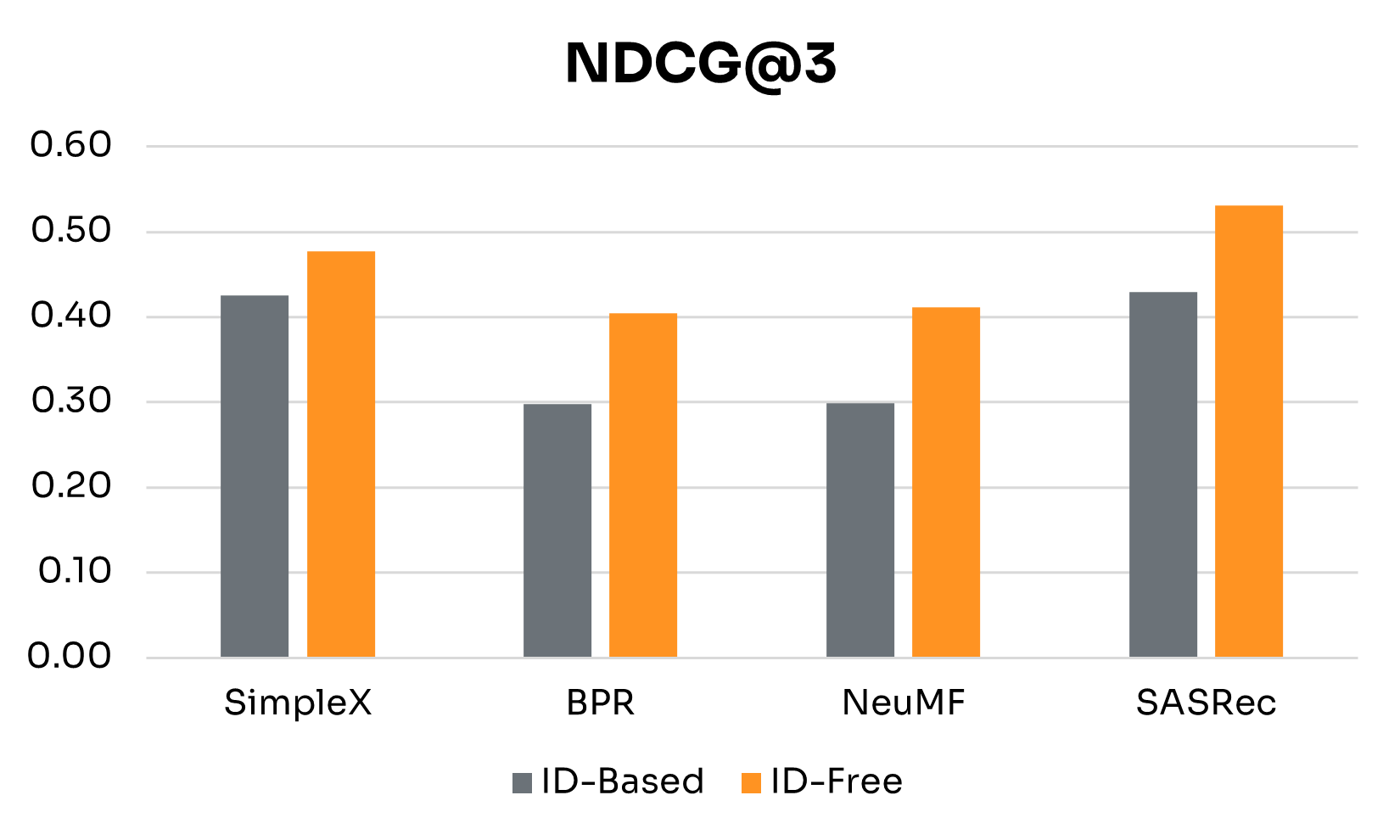
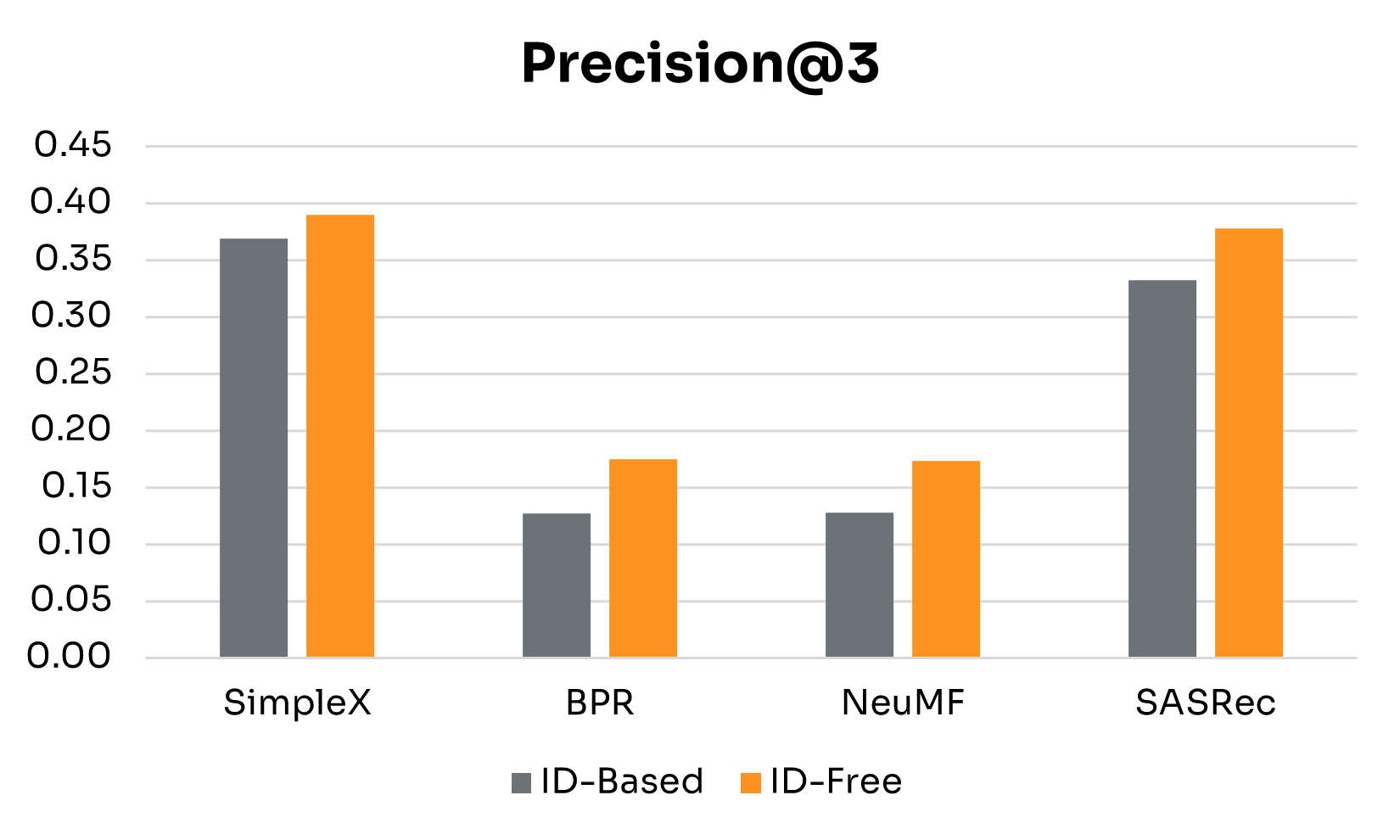
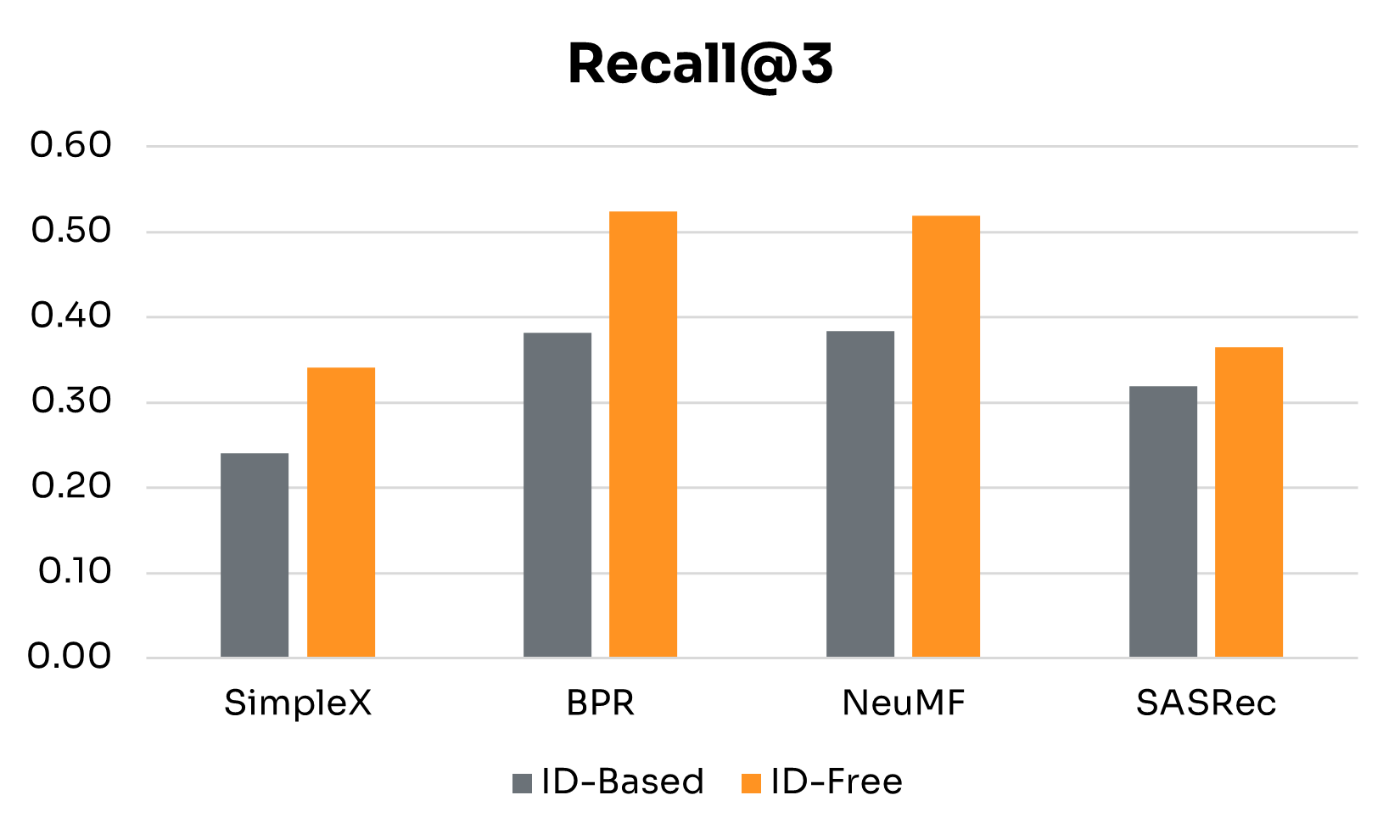
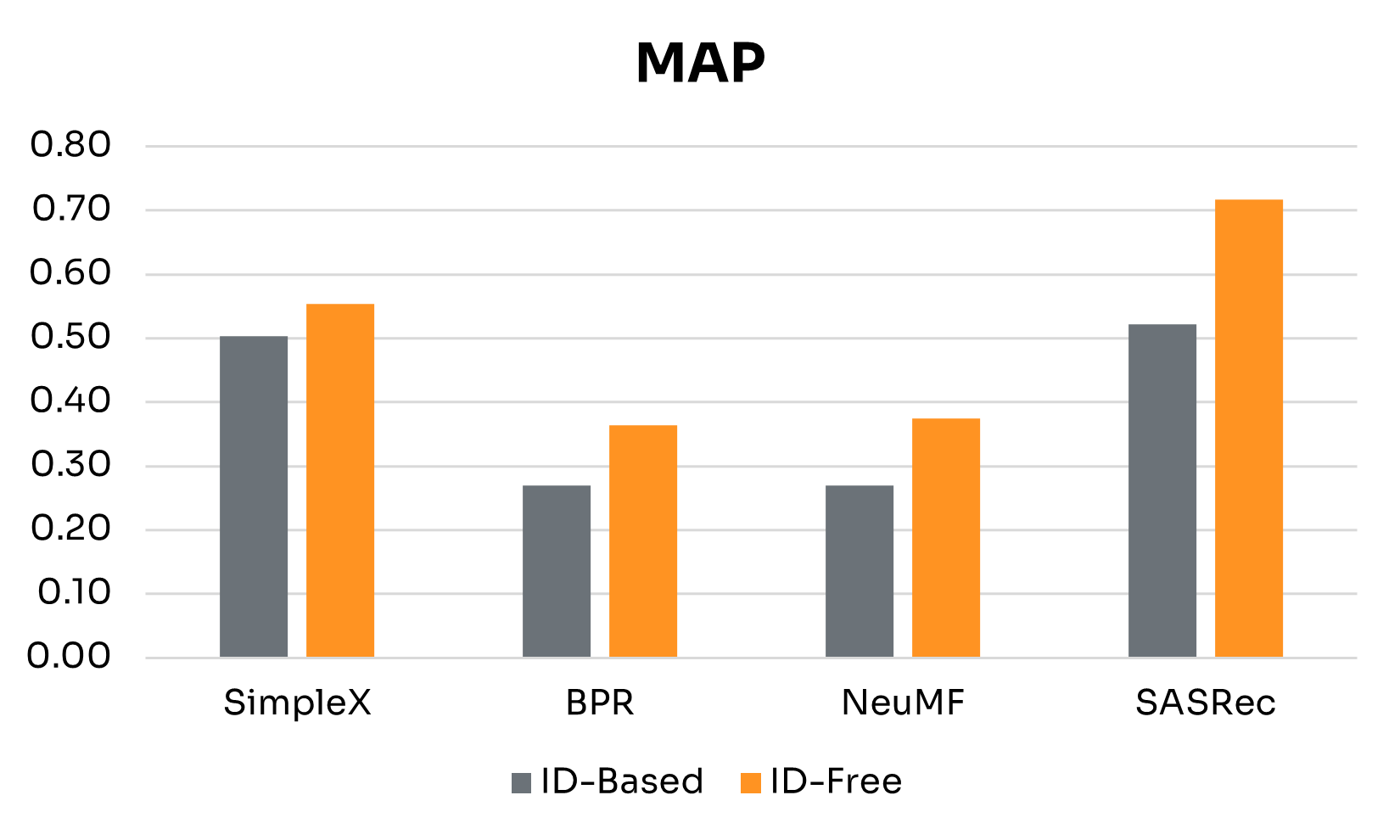
| Performance Gains | SimpleX | BPR | NeuMF | SASRec |
|---|---|---|---|---|
| NDCG@3 | 0.051 | 0.107 | 0.113 | 0.102 |
| Precision@3 | 0.021 | 0.047 | 0.045 | 0.045 |
| Recall@3 | 0.101 | 0.142 | 0.136 | 0.046 |
| MAP | 0.051 | 0.095 | 0.105 | 0.195 |
Figure 3 presents side-by-side results for ID-Free and ID-Based variants at the 4-week window. Table 2 summarizes detailed performance gains across key metrics. The main findings are:
• Semantic Embeddings Consistently Boost Performance: Across all four models, ID-Free variants outperformed ID-Based versions on every metric. This shows that embeddings derived from rich metadata capture more generalizable representations of users and nudges than raw IDs, yielding higher-quality recommendations regardless of architecture.
• Magnitude of Gains Depends on Architecture: BPR and NeuMF, the simpler non-sequential models, saw the largest boosts, especially in NDCG@3, Precision@3, and Recall@3. SimpleX showed more modest improvements, with its largest gain in Recall@3. SASRec recorded the biggest increase in MAP, though with smaller gains in Recall@3.
Overall, these results underscore the advantages of ID-Free modeling in dynamic, data-rich environments like digital health. By leveraging semantic embeddings, ID-Free models not only improve performance but also offer a more flexible and robust framework free from the constraints of traditional user and nudge identifiers.
This analysis highlights the real-world viability of ID-Free recommendation models. Performance generally improved with additional training data, peaking around the 4-week window. SASRec stood out as the most stable and consistently high-performing model, effectively capturing long-term user behavior through its sequential, attention-based architecture.
In terms of computational trade-offs, simpler models like BPR were highly efficient but limited in performance. SASRec provided the best balance of accuracy and efficiency, while SimpleX achieved strong results but at a much higher computational cost. The optimal choice depends on factors such as data availability, retraining frequency, and infrastructure constraints.
Most importantly, the ablation study demonstrated that semantic embeddings consistently improved performance across all architectures. This indicates that the strength of ID-Free models lies not only in their design but in their ability to capture richer, more generalizable representations of users and nudges. Together, these findings position ID-Free approaches as a strong candidate for digital health recommendation systems, offering adaptability to cold-start scenarios and enabling robust, high-quality personalization.

Jodi Jodi is a Data Scientist at CueZen, where she develops machine learning models to improve engagement and drive positive health behaviors.
The $185 billion wearables industry has a retention problem that threatens its entire value proposition. Here’s how AI-powered behavioral science can fix it.
Your Fitbit is probably in a drawer somewhere. You’re not alone—research shows that approximately 30% of wearable users abandon their devices within 6 months, with some studies documenting abandonment rates as high as 50% within just two weeks [1,2]. This isn’t a user problem; it’s a business model problem.
The current wearables paradigm treats engagement as a byproduct of hardware features. Companies invest billions in better sensors, longer battery life, and sleeker designs, then wonder why users lose interest once the novelty fades. Meanwhile, the real opportunity—transforming raw biometric data into sustained behavioral change—remains largely untapped.
Most wearables excel at data collection but fail spectacularly at insight generation. Your device knows you slept poorly, walked 3,000 steps, and had an elevated heart rate during your morning meeting. But it can’t tell you why these patterns emerged or what to do about them tomorrow.
This represents a fundamental misunderstanding of human motivation. While health outcomes are often simplified as 60% behavioral, 30% genetic, and 10% medical care [3], the key insight for wearables is that the vast majority of health improvement comes from modifiable behavioral factors—precisely the domain where current devices provide minimal value beyond basic tracking.
The gap isn’t technological; it’s methodological. Raw data doesn’t drive behavior change. Contextual narrative does.
2025 marks an inflection point where AI-powered behavioral interventions are moving from research labs to commercial deployment at population scale. The evidence is compelling:
Real-World Impact: CZ’s NudgeRank system, deployed across Singapore’s 1.1 million users, demonstrates that AI-driven personalized nudging achieves 6.17% increases in daily steps and 7.61% increases in exercise minutes—statistically significant improvements that persist across 12-week periods [4].
Industry Shift: Major players are pivoting toward AI coaching. Oura launched its AI Advisor, WHOOP deployed an AI coach, and Thrive AI Health (OpenAI’s collaboration with Thrive Global) is delivering hyper-personalized coaching at scale [5]. These aren’t experimental features—they’re core product strategies.
Economic Validation: Healthcare organizations implementing AI personalization are achieving 5-10% cost reductions while improving outcomes [6]. The business case extends beyond device sales to subscription revenue and B2B partnerships.
Current gamification strategies—badges, streaks, social comparisons—rely on extrinsic motivation that research shows diminishes over time [7]. Sustainable engagement requires intrinsic motivation, which emerges from three psychological needs: autonomy, competence, and relatedness.
AI enables a fundamentally different approach:
Adaptive Personalization: Instead of generic “10,000 steps” goals, AI can recommend “15 minutes of walking after lunch” based on your specific sleep patterns, work schedule, and stress indicators.
Predictive Coaching: Rather than reactive feedback (“You walked 5,000 steps yesterday”), AI can provide forward-looking guidance (“Your trend suggests higher illness risk next week—consider prioritizing sleep”).
Contextual Intelligence: AI understands that suggesting a workout during a stressful work deadline is counterproductive. It learns when to encourage, when to back off, and when to pivot strategies entirely.
The path forward requires abandoning the hardware-centric model for an outcomes-centric approach. Consider three market segments that need this evolution:
Corporate Wellness Programs: Employers spend $13.6 billion annually on wellness initiatives with minimal ROI measurement [8]. AI-powered behavioral outcomes provide measurable engagement metrics, health improvements, and cost reductions that justify premium pricing.
Health Insurance Partnerships: Insurers need proven risk reduction strategies. Platforms like CueZen demonstrate that sustained behavioral change translates to reduced healthcare utilization and lower claim costs—creating immediate value alignment.
Consumer Subscriptions: Users abandon devices but will pay for results. The shift from “fitness tracker” to “AI health coach” transforms the value proposition from hardware features to behavioral outcomes.
Different consumer segments require different approaches. Recent research identifies five distinct wellness personas, from “maximalist optimizers” (25% of consumers, 40% of spending) who actively seek cutting-edge AI solutions, to “health strugglers” who need simplified, highly supportive interventions [9].
For product managers and executives ready to make this transition:
Phase 1: Enhanced Analytics
• Implement behavior pattern recognition
• Develop personalized insight algorithms
• A/B test different coaching approaches
Phase 2: AI Integration
• Deploy conversational AI interfaces
• Build predictive modeling capabilities
• Create adaptive intervention systems
Phase 3: Outcomes Partnership
• Establish enterprise pilot programs
• Develop B2B pricing models based on health outcomes
• Scale proven interventions across populations
Phase 4: Platform Evolution
• Transition from device sales to subscription revenue
• Build ecosystem partnerships with healthcare providers
• Establish data-driven ROI measurement frameworks
The companies that crack this challenge first will capture disproportionate value. The technical barriers are surmountable—Graph Neural Networks, large language models, and behavioral science frameworks already exist. The competitive moat lies in execution: building systems that understand individual behavioral patterns and deliver interventions that actually work.
This isn’t about incremental improvement to existing fitness trackers. It’s about reimagining wearables as behavioral change platforms that happen to include sensors, rather than sensor platforms that happen to include basic feedback.
The question isn’t whether this transformation will happen—it’s whether your company will lead it or follow it.
[1] Attig, C., & Franke, T. (2019). Abandonment of personal quantification: A review and empirical study investigating reasons for wearable activity tracking attrition. Computers in Human Behavior, 102, 223-237. https://www.sciencedirect.com/science/article/abs/pii/S0747563219303127
[2] Cadmus-Bertram, L. A., et al. (2015). Randomized trial of a Fitbit-based physical activity intervention for women. American Journal of Preventive Medicine, 49(3), 414-418.
[3] GoInvo Health Determinants Analysis. (2023). Determinants of Health Visualized. https://www.goinvo.com/vision/determinants-of-health/
[4] Chiam, J., Lim, A., & Teredesai, A. (2024). NudgeRank: Digital Algorithmic Nudging for Personalized Health. KDD ’24 Proceedings.
[5] Healthcare IT News. (2025). 2025: AI enhances personalized care; caregiver experience in spotlight. https://www.healthcareitnews.com/news/2025-ai-enhances-personalized-care-caregiver-experience-spotlight
[6] Appinventiv. (2025). Personalization in Healthcare: AI-Driven Predictive Analytics Guide. https://appinventiv.com/blog/personalization-in-healthcare/
[7] Deci, E. L., & Ryan, R. M. (2000). The “what” and “why” of goal pursuits: Human needs and the self-determination of behavior. Psychological Inquiry, 11(4), 227-268.
[8] Kaiser Family Foundation. (2023). Employer Health Benefits Survey.
[9] McKinsey & Company. (2025). Future of wellness trends survey 2025. https://www.mckinsey.com/industries/consumer-packaged-goods/our-insights/future-of-wellness-trends
Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.

As behavioral health utilization reaches unprecedented levels, the intersection of AI-powered early intervention and reimbursement reform represents healthcare’s next critical evolution.
Healthcare is experiencing a behavioral health surge of historic proportions. Claims for inpatient behavioral health services jumped nearly 80% between January 2023 and December 2024, while outpatient services grew by 40% over the same period¹. This isn’t just a statistical anomaly—it represents a fundamental shift in healthcare demand that’s reshaping the industry’s cost structure and care delivery models.
The numbers tell a stark story of growing need, colliding with systemic barriers. Behavioral health spending has doubled over the past five years and now represents over 3% of total healthcare costs². One in three health plan actuaries now identify behavioral health services as a top cost inflator, with expected trends of 10-20% annually¹. Yet despite this surge in demand and spending, access barriers persist that push care toward the most expensive interventions.
The root of this paradox lies in a reimbursement system that hasn’t evolved to match the reality of behavioral health care delivery. Insurance reimbursements for behavioral health visits average 22% lower than for medical or surgical office visits³, creating systematic disincentives for provider participation and forcing patients toward crisis-level interventions that could have been prevented through earlier, less intensive care.
Unprecedented growth in mental health and substance use services
Jan 2023 – December 2024
24-Month Growth Period
Jan 2023 -> December 2024
Claims data analysis across commercial health plans


The behavioral health reimbursement gap isn’t just an academic policy concern—it’s driving real-world access problems that ultimately increase total healthcare costs. Research demonstrates that patients seeking behavioral health care are 10.6 times more likely to be forced out-of-network compared to patients of specialty physicians³. This access barrier creates a perverse dynamic where preventive and early intervention services become economically inaccessible, while crisis interventions remain the primary point of system entry.
The financial incentive structure inadvertently encourages exactly the opposite of what evidence-based care recommends. When patients can’t access timely outpatient behavioral health services due to network adequacy issues driven by low reimbursement rates, they often present later with higher acuity needs requiring emergency department visits, inpatient psychiatric admissions, or crisis stabilization services—all significantly more expensive than the preventive care that could have addressed their needs earlier.
Medicare’s approach to reimbursement further compounds this problem. Studies show Medicare pays physicians 3-5 times more for procedural work compared to cognitive work⁴, systematically undervaluing the critical thinking, analysis, and decision-making that defines behavioral health care. This has led to a disproportionate number of psychiatrists opting out of Medicare—42% of all physician opt-outs despite psychiatrists representing a small fraction of the physician workforce⁴.
The cascade effect extends beyond individual patient outcomes. Untreated mental illness creates substantial economic burden; research in Indiana found that untreated mental illness cost the state $4.2 billion in direct, indirect, and societal costs—approximately 1% of the state’s gross domestic product³. When reimbursement policies make preventive behavioral health care economically unviable, the system shifts these costs to emergency services, criminal justice, and social support systems.
While the healthcare industry has focused heavily on expanding teletherapy access, the next frontier lies in AI-enabled early identification and intervention. Advanced AI systems can detect behavioral health risks through patterns that would be invisible to traditional screening methods, enabling intervention before crisis-level care becomes necessary.
Modern AI platforms analyze multiple data streams to identify emerging behavioral health needs. Wearable devices provide continuous monitoring of sleep patterns, physical activity, heart rate variability, and other physiological markers that correlate with mood disorders and stress levels. Electronic health record data reveals patterns in healthcare utilization, medication adherence, and documented symptoms that can predict behavioral health crises weeks or months in advance.
Digital interaction patterns offer another layer of early warning signals. Changes in smartphone usage, social media engagement, communication patterns, and app interaction can indicate developing depression, anxiety, or other behavioral health conditions. When combined with validated screening tools and clinical assessments, these AI-driven insights enable healthcare systems to identify at-risk individuals and deploy targeted interventions before acute care becomes necessary.
The sophistication of these systems extends beyond simple alerts to personalized intervention strategies. CZ’s NudgeRank™ platform, deployed at population scale in Singapore, demonstrates how AI can deliver personalized behavioral health interventions to over 1.1 million individuals daily. The system uses Graph Neural Networks combined with dynamic Knowledge Graphs to understand individual risk factors, preferences, and contextual circumstances, enabling precisely timed interventions that address specific behavioral health needs.
Controlled studies validate the effectiveness of this approach. Singapore’s deployment showed 2.75 times higher engagement compared to standard interventions, with measurable improvements in health behaviors that correlate with reduced behavioral health risks⁵. When applied specifically to behavioral health, such systems can identify individuals showing early signs of depression, anxiety, or substance use disorders and deploy evidence-based interventions before crisis intervention becomes necessary.
For payers, the financial argument for AI-enhanced behavioral health engagement is compelling when viewed through the lens of total cost of care rather than per-service reimbursement. The current system’s focus on minimizing individual service costs creates a penny-wise, pound-foolish dynamic that increases overall healthcare spending while failing to address underlying behavioral health needs.
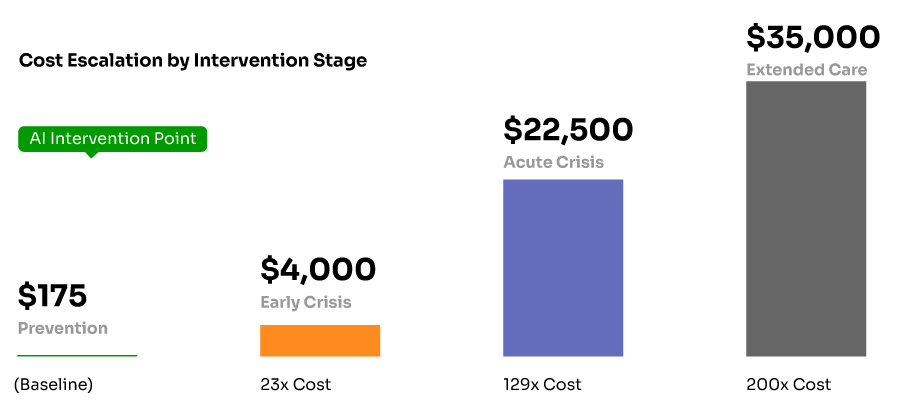
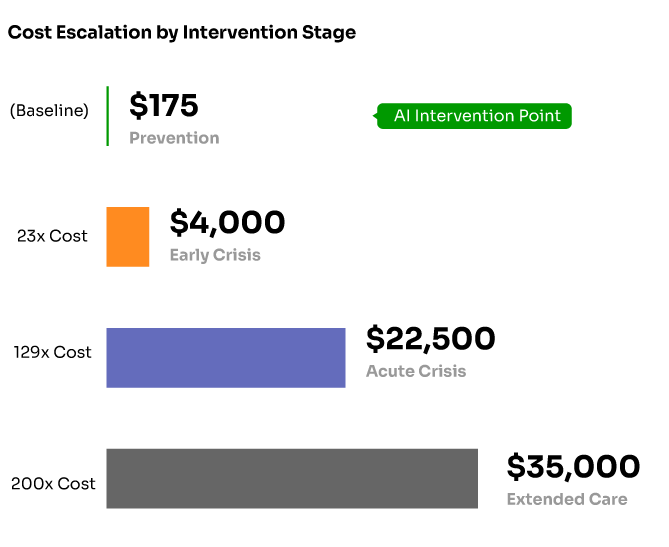
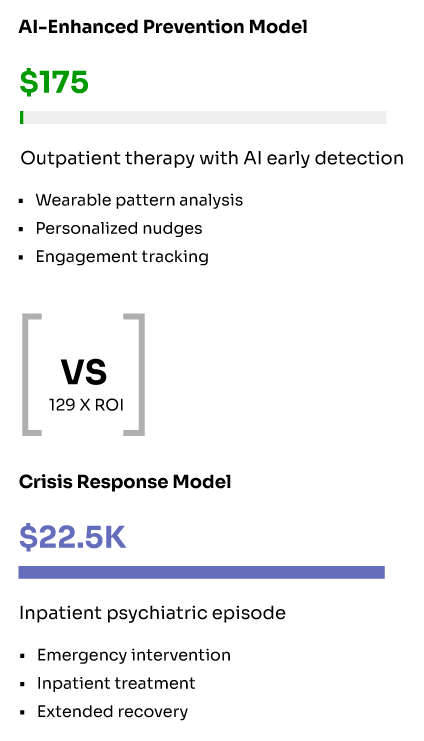
Consider the cost differential between prevention and crisis intervention. A typical outpatient therapy session might cost $150-200, while an emergency department visit for behavioral health crisis can cost $3,000-5,000, and inpatient psychiatric admission can reach $15,000-30,000 per episode. When AI systems can identify at-risk individuals and connect them with appropriate outpatient care, the return on investment becomes clear even with current reimbursement disparities.
The business case strengthens when considering the broader impact of untreated behavioral health conditions on total medical costs. Individuals with untreated depression, anxiety, or substance use disorders have significantly higher utilization of emergency services, primary care, and specialty medical care. They’re more likely to be non-adherent to medications for chronic conditions, leading to complications and expensive interventions. They have higher rates of workplace absence and reduced productivity, creating costs for employer-sponsored health plans beyond direct medical expenses.
AI-powered early intervention addresses these systemic cost drivers through targeted, personalized engagement that increases the likelihood of successful behavioral health treatment. Rather than waiting for individuals to reach crisis level and require expensive emergency interventions, AI systems can identify emerging risks and deploy appropriate interventions that prevent escalation while building sustainable behavioral health management strategies.
Real-world implementations demonstrate measurable returns. Healthcare organizations using AI-driven personalization for behavioral health interventions report improved engagement rates, reduced no-show rates for behavioral health appointments, and decreased utilization of crisis services. The Singapore deployment achieved a 20% reduction in program management costs while delivering improved outcomes⁵, demonstrating that AI-enhanced behavioral health engagement can simultaneously improve care quality and reduce administrative burden.
Dramatic cost escalation in behavioral health intervention

Implementing AI-driven behavioral health interventions at payer scale requires sophisticated technical infrastructure designed specifically for healthcare environments. Unlike consumer wellness applications, healthcare AI systems must meet stringent privacy, security, and regulatory requirements while integrating with existing clinical workflows and payer systems.
Modern platforms deploy entirely within customer cloud environments, ensuring complete data sovereignty while maintaining enterprise-grade security. The CZ platform, for example, operates within customer Azure tenants without requiring any Personal Identifiable Information (PII), using pseudonymous identifiers throughout the system⁵. This approach addresses privacy concerns while enabling the comprehensive data integration necessary for effective AI-driven behavioral health interventions.
The technical architecture must support real-time processing of multiple data streams while maintaining sub-second response times for millions of daily interventions. Production deployments demonstrate the feasibility of this approach—Singapore’s system processes over 1.1 million daily personalized interventions using scalable cloud infrastructure⁵. The system integrates with 30+ wearable device manufacturers, electronic health record systems, and existing healthcare applications through unified APIs.
Critical to success is the platform’s ability to adapt continuously based on individual responses and population-level outcomes. Machine learning algorithms update daily based on engagement patterns, intervention effectiveness, and changing individual circumstances. This continuous optimization ensures that behavioral health interventions remain relevant and effective as individual needs evolve and population health patterns change.
The regulatory landscape surrounding behavioral health reimbursement is evolving rapidly, creating both opportunities and challenges for AI-enhanced interventions. The September 2024 finalization of new Mental Health Parity and Addiction Equity Act (MHPAEA) regulations represents the most significant advancement in behavioral health parity enforcement in over a decade⁶.
These regulations require health plans to conduct comparative analyses measuring the impact of non-quantitative treatment limitations (NQTLs) on behavioral health access compared to medical/surgical benefits. Plans must collect and evaluate data on material differences in access and take reasonable action to address disparities. This includes evaluating network composition, out-of-network reimbursement rates, and medical management techniques—all areas where AI-enhanced interventions can provide objective, data-driven evidence of improved outcomes.
The new regulations also prohibit plans from using discriminatory information or standards that systematically disfavor behavioral health benefits. This creates opportunities for AI systems that can demonstrate improved clinical outcomes and cost-effectiveness compared to traditional behavioral health management approaches. Plans that can show their AI-enhanced behavioral health programs improve access while maintaining quality may find regulatory support for innovative reimbursement models.
However, regulatory uncertainty remains. The current administration has indicated it will not enforce certain Biden-era mental health parity regulations, creating potential inconsistency in enforcement standards³. This regulatory environment makes it critical for AI-enhanced behavioral health programs to demonstrate clear clinical value and cost-effectiveness independent of specific regulatory requirements.
States are increasingly taking independent action on behavioral health parity enforcement. New Mexico now requires regulators to review insurers’ reimbursement rate methodologies when assessing network adequacy. Oregon mandates annual reporting on how behavioral health provider reimbursement rates compare with other providers⁷. These state-level initiatives create additional opportunities for AI-enhanced programs that can demonstrate superior outcomes and cost-effectiveness.
Successful implementation of AI-enhanced behavioral health programs requires strategic integration with existing clinical workflows and payer operations rather than standalone deployment. Health plans should approach implementation through a phased strategy that builds on current behavioral health management capabilities while introducing AI-driven enhancements gradually.
The initial phase should focus on high-impact use cases with clear measurement criteria. Medication adherence for behavioral health medications represents an ideal starting point, as it offers objective measures of engagement and clinical outcomes while addressing a documented problem area. AI systems can identify patterns indicating adherence challenges and deploy personalized interventions that address specific barriers—whether related to side effects, cost concerns, or routine disruption.
Crisis prevention represents another high-value implementation area. AI systems can analyze patterns in healthcare utilization, prescription history, and documented symptoms to identify individuals at elevated risk for behavioral health crises. Early identification enables deployment of intensive case management, peer support, or clinical outreach that prevents emergency department visits and inpatient psychiatric admissions.
Integration with existing care management platforms is critical for sustainable implementation. Rather than creating separate AI-driven behavioral health programs, successful deployments integrate AI insights into existing clinical workflows, providing care managers and behavioral health providers with actionable intelligence that enhances their decision-making rather than replacing it.
Data governance and privacy protection require careful attention throughout implementation. Health plans should establish clear protocols for data use, algorithmic decision-making, and clinical oversight that ensure AI recommendations enhance rather than substitute for clinical judgment. Regular auditing of AI system performance and bias detection helps maintain both clinical effectiveness and regulatory compliance.
The convergence of unprecedented behavioral health demand and advanced AI capabilities creates a narrow window for transformative change in how healthcare systems approach behavioral health care. However, realizing this potential requires coordinated action across regulatory, reimbursement, and technology domains.
Reimbursement reform must move beyond simple rate increases to outcome-based models that reward effective prevention and early intervention. Value-based contracts specifically designed for behavioral health could compensate providers based on prevented crisis interventions, improved functional outcomes, and sustained engagement rather than just volume of services provided. AI systems that can accurately measure and predict these outcomes enable the data-driven accountability necessary for such contracts.
Technology standards and interoperability requirements need updating to support AI-enhanced behavioral health interventions. Current healthcare data exchange standards weren’t designed for the continuous, real-time data flows necessary for effective AI-driven early intervention. Developing standards that enable secure sharing of behavioral health-relevant data while maintaining privacy protections will be critical for scaling AI interventions across different healthcare systems and payers.
Clinical integration standards should evolve to incorporate AI-driven insights into established behavioral health treatment protocols. This includes training requirements for clinicians working with AI-enhanced systems, clinical decision support standards that incorporate AI recommendations appropriately, and quality measures that assess the effectiveness of AI-augmented behavioral health care.
The ultimate goal is creating a behavioral health care system that intervenes early, personalizes treatment approaches, and measures success through improved population mental health rather than just individual service delivery. This requires moving beyond the current crisis-responsive model to a predictive, preventive approach enabled by AI technology and supported by reimbursement policies that reward effective population health management.
For Health Plans:
• Pilot AI-enhanced behavioral health programs in high-impact areas like medication adherence and crisis prevention
• Develop value-based contracts for behavioral health that reward prevention and early intervention
• Invest in data integration capabilities that enable comprehensive behavioral health risk assessment
• Establish clinical governance frameworks for AI-driven behavioral health interventions
For Policymakers:
• Strengthen mental health parity enforcement with specific attention to AI-enhanced intervention programs
• Develop reimbursement models that reward effective behavioral health population management
• Create regulatory frameworks that encourage innovation while maintaining clinical oversight
• Support research into AI-driven behavioral health interventions and their long-term outcomes
For Healthcare Organizations:
• Integrate AI-driven behavioral health risk assessment into existing clinical workflows
• Develop partnerships with AI platform providers that demonstrate population-scale effectiveness
• Train clinical staff on incorporating AI insights into behavioral health treatment planning
• Establish measurement systems that track both clinical outcomes and cost-effectiveness
The behavioral health surge represents both healthcare’s greatest challenge and its most significant opportunity for transformation. The 80% growth in inpatient behavioral health utilization and 40% growth in outpatient services reflects a population in crisis that current care delivery models cannot adequately address¹. Yet this same surge creates the data foundation necessary for AI systems to identify patterns, predict risks, and deploy interventions that could prevent much of this crisis-level care.
The 22% reimbursement gap between behavioral health and medical/surgical services³ represents a systemic barrier that AI-enhanced interventions can help overcome by demonstrating superior cost-effectiveness and clinical outcomes. When AI systems can prevent expensive crisis interventions through targeted early intervention, the business case for investing in behavioral health becomes compelling even within current reimbursement constraints.
The path forward requires coordinated evolution across technology, regulation, and reimbursement. AI platforms like CZ’s NudgeRank™ demonstrate that population-scale behavioral health intervention is technically feasible and clinically effective⁵. Regulatory frameworks are evolving to support outcome-based behavioral health approaches. The missing piece is reimbursement reform that aligns financial incentives with the preventive, personalized approach that AI enables.
Healthcare organizations that successfully integrate AI-enhanced behavioral health interventions will not only improve clinical outcomes and reduce costs—they will help transform behavioral health care from a crisis-responsive system to a predictive, preventive model that addresses mental health challenges before they become mental health crises. This transformation represents healthcare’s next evolution and society’s best hope for addressing the behavioral health challenges that affect millions of individuals and communities.
The evidence is clear, the technology exists, and the need is urgent. The question is not whether AI-enhanced behavioral health intervention will become standard practice, but how quickly healthcare leaders will act to implement these solutions and advocate for the reimbursement reforms necessary to support them at scale.
1. PwC Health Research Institute. (2025). Medical cost trend: Behind the numbers 2025. PwC US.https://www.pwc.com/us/en/industries/health-industries/library/behind-the-numbers.html
2. PwC US. (2025). PwC’s 2025 Medical cost trend report reveals rising healthcare costs. https://www.pwc.com/us/en/industries/health-industries/health-research-institute/next-in-health-podcast/pwc-2025-medical-cost-trend-report-reveals-rising-healthcare-costs.html
3. American Psychological Association Services. (2025). New Policies Affecting Access to Mental Health Care. https://updates.apaservices.org/new-policies-affecting-access-to-mental-health-care
4. Mental Health America. (2025). Fix the foundation: Unfair rate setting leads to inaccessible mental health care. https://mhanational.org/blog/fix-the-foundation-unfair-rate-setting-leads-to-inaccessible-mental-health-care/
5. Chiam, J., Lim, A., & Teredesai, A. (2024). NudgeRank: Digital Algorithmic Nudging for Personalized Health. KDD ’24 Conference Proceedings.
6. U.S. Department of Labor. (2024). Fact Sheet: Final Rules under the Mental Health Parity and Addiction Equity Act (MHPAEA). https://www.dol.gov/agencies/ebsa/about-ebsa/our-activities/resource-center/fact-sheets/final-rules-under-the-mental-health-parity-and-addiction-equity-act-mhpaea
7. The Commonwealth Fund. (2023). Building on Behavioral Health Parity: State Options to Strengthen Access to Care. https://www.commonwealthfund.org/blog/2023/building-behavioral-health-parity-state-options-strengthen-access-care
Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.
The next evolution of healthcare isn’t just about lowering copays – it’s about making those incentives psychologically compelling and actionable at scale.
Value-Based Insurance Design (V-BID) is expanding rapidly across healthcare. CMS has approved numerous Medicare Advantage V-BID demonstration programs that reduce or eliminate cost-sharing for high-value services like diabetes management medications, chronic disease monitoring, and preventive screenings. Employer-sponsored plans increasingly adopt similar models, recognizing that targeted financial incentives can theoretically improve health outcomes while managing long-term costs.
However, a significant gap exists between financial incentive availability and actual behavior change. Medication adherence rates for chronic conditions consistently remain around 50% across multiple systematic reviews, even when cost barriers are substantially reduced¹. Preventive care utilization often stays below optimal levels despite generous coverage improvements.
This disconnect reveals a fundamental challenge: financial incentives alone don’t reliably change behavior.
The issue isn’t the financial incentive design – it’s the missing behavioral layer that could transform economic motivation into sustained health actions.
Despite generous V-BID programs, medication adherence rates for chronic conditions remain around 50% according to systematic reviews¹. Preventive care utilization stays low even when cost-sharing is eliminated. The disconnect between financial incentives and actual behavior change reflects well-documented principles from behavioral economics research.
Thaler and Sunstein’s foundational work on choice architecture demonstrates that humans struggle with temporal discounting – the tendency to value immediate costs and benefits more heavily than future ones². A $30 copay reduction for diabetes medication might save $360 annually, but this abstract future benefit rarely competes with the immediate friction of complex medication schedules or side effects.
Research on health behavior interventions reveals several key factors for effectiveness:
Timing Matters: Just-in-Time Adaptive Interventions (JITAIs) show superior outcomes when delivered at optimal moments rather than on fixed schedules³. A medication reminder aligned with individual routines proves more effective than generic periodic messaging.
Personalization Drives Engagement: Systematic reviews of digital health interventions consistently find that personalized approaches achieve higher engagement rates than one-size-fits-all messaging⁴.
Loss Framing Effects: Meta-analyses confirm that loss-framed messages can be more motivating than gain-framed messages for certain health behaviors⁵.
Social Influence: Social comparison feedback has demonstrated effectiveness across multiple health behavior domains, though effects vary by population and context⁶.
Traditional V-BID programs reduce financial barriers but lack the behavioral intelligence to make those benefits psychologically compelling at the individual level.
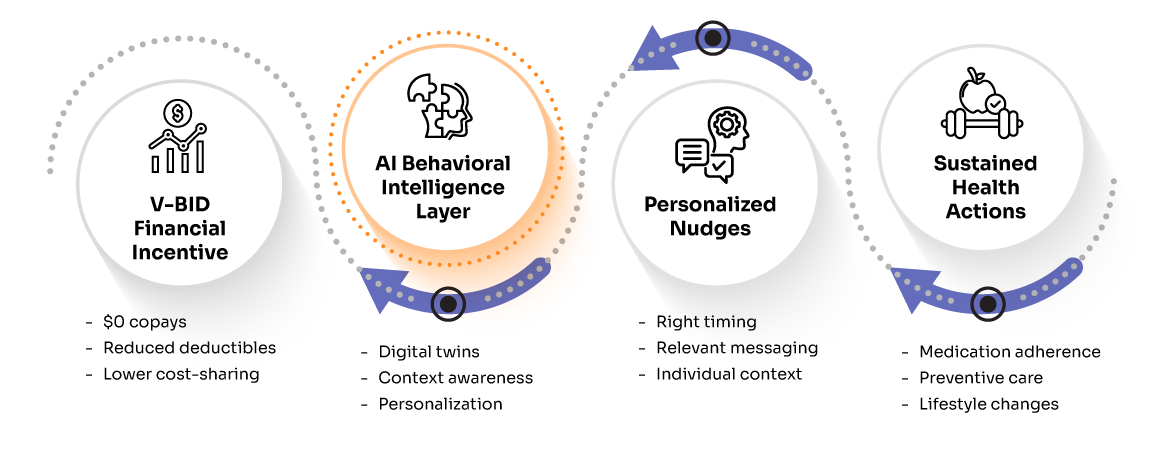
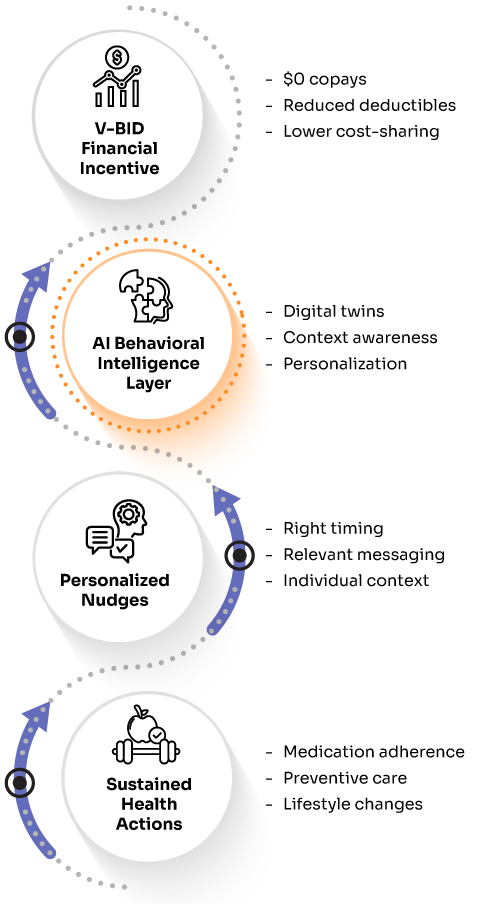
Digital therapeutics powered by artificial intelligence can transform V-BID from a blunt financial instrument into a precision behavioral tool. Rather than hoping members will spontaneously optimize their health behaviors because costs are lower, AI systems can actively guide them toward those behaviors with personalized, context-aware interventions.
The evidence for this approach comes from large-scale real-world deployments. CZ’s NudgeRank™ platform, currently operational in Singapore’s population health program, demonstrates AI-driven behavioral intervention at unprecedented scale. The system delivers personalized health nudges to over 1.1 million citizens daily through Singapore’s Healthy 365 mobile app.
A controlled study of 84,764 participants receiving personalized nudges versus 84,903 matched controls showed statistically significant improvements: 6.17% increase in daily steps and 7.61% increase in weekly moderate-to-vigorous physical activity over 12 weeks⁷. The platform achieved a 13.1% nudge open rate compared to baseline rates of 4%.

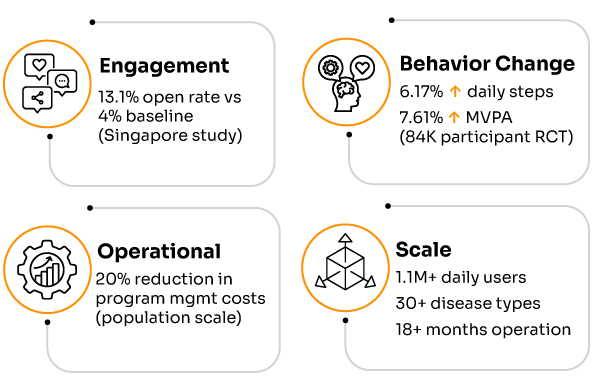
The system combines Graph Neural Networks with dynamic Knowledge Graphs to create comprehensive member profiles integrating demographics, clinical data, lifestyle patterns from wearables, and behavioral preferences. This enables understanding not just what behaviors to encourage, but when, how, and why to encourage them for each individual.
Key to effectiveness is real-time adaptation. The Singapore deployment processes data from 30+ wearable device types and updates behavioral interventions based on changing member contexts and preferences. The system operates entirely within Singapore’s government cloud environment, maintaining data sovereignty while scaling to population-level deployment.
For payers, integrating behavioral AI with V-BID programs addresses multiple business imperatives with measurable outcomes:
Operational Efficiency: The Singapore deployment achieved a 20% reduction in program management costs through AI automation while delivering improved health outcomes⁸. When member engagement increases 2.75-fold compared to standard approaches, administrative costs per successful intervention decrease substantially.
Quality Metrics Enhancement: Medicare Advantage plans face increasing pressure on STAR ratings, particularly around medication adherence and preventive care utilization. AI-powered interventions that demonstrably improve these behaviors through personalized engagement directly impact quality scores.
Scalability Without Proportional Cost Increase: Traditional health coaching requires linear scaling of human resources. AI systems can handle millions of personalized interventions daily with fixed infrastructure costs. The Singapore platform processes over 1.1 million daily nudges with a system that scales horizontally on commodity cloud infrastructure.
Measurable Health Outcomes: Controlled studies provide quantifiable evidence of intervention effectiveness. The 6.17% increase in daily steps and 7.61% increase in physical activity minutes represent concrete improvements that translate to reduced long-term healthcare utilization for chronic conditions.
Platform Integration
Behavioral Content
Operations
Enhanced Engagement
Measurable Behavior Change
Operational Efficiency
Population Scale
Quality Metrics Improvement
Medical Cost Management
Member Experience
Strategic Position
Technical Risk
Clinical Risk
Regulatory Risk
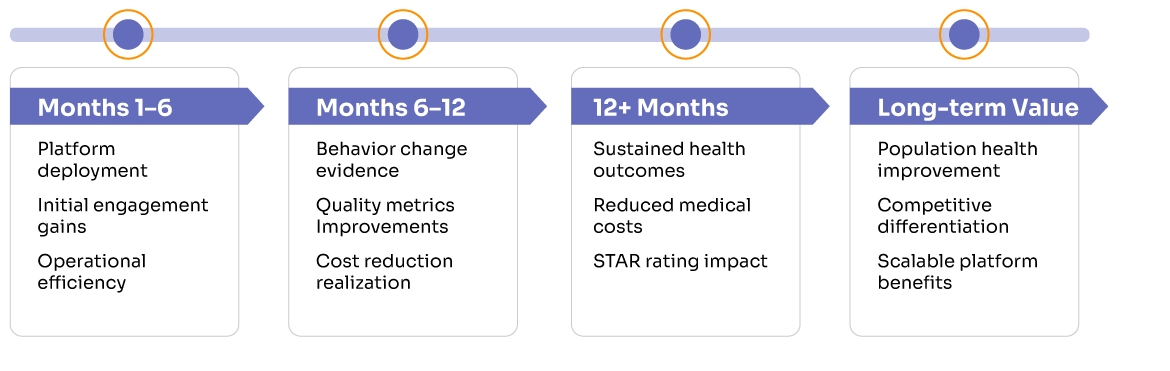
Integration Capabilities: Modern platforms deploy entirely within payer environments, ensuring data never leaves their secure infrastructure. CZ’s platform, for example, runs in customer Azure tenants with government-grade security while integrating with existing EHR systems and wearable device ecosystems.
Advanced implementations combine V-BID financial structures with evidence-based behavior change techniques. This involves moving beyond simple copay reductions to create what behavioral economists call “choice architecture” – environments that make healthy behaviors easier to adopt and maintain.
For medication adherence, documented approaches include:
For preventive care, successful strategies involve:
The NHS implementation for gestational diabetes management illustrates integration potential: unified platforms combining EHR data, digital therapeutics, and lifestyle monitoring to provide personalized interventions while reducing notification fatigue and improving care coordination.
Implementing behavioral AI at payer scale requires robust technical infrastructure designed for healthcare environments. Production deployments demonstrate specific architectural requirements and capabilities.
The CZ platform exemplifies this approach, deploying entirely within customer cloud environments (Microsoft Azure tenants) to ensure complete data sovereignty while maintaining enterprise security standards. Key architectural components include:
Device Integration: Documented compatibility with 30+ wearable device manufacturers including Apple Health, Google Fit, Fitbit, Apple Watch, and major fitness tracker brands through unified API interfaces.
Privacy-First Design: Systems operate without any Personal Identifiable Information (PII), using pseudonymous masked IDs throughout. All processing occurs within customer environments with no data egress to external systems.
Scalability Evidence: CZ’s Singapore deployment processes over 1.1 million daily personalized interventions using a 10-node Kubernetes cluster, with linear scaling demonstrated up to 19 billion candidate user-nudge pairs.
Automated Operations: Daily model updates completing in 90-150 minutes, with 18+ months of continuous production operation demonstrating system reliability and automated failure recovery.
Healthcare Integration: Proven integration with EHR systems (demonstrated in NHS gestational diabetes management) and existing payer infrastructure without disrupting operational workflows.
These technical capabilities matter because payer adoption requires confidence that behavioral AI can integrate with existing systems without compromising security or operational stability.
The healthcare industry’s tendency toward fragmented point solutions has created intervention fatigue among both providers and members. The winning approach integrates behavioral science directly into existing V-BID structures rather than adding another layer of complexity.
This means viewing digital therapeutics not as separate wellness programs, but as the behavioral intelligence layer that makes V-BID programs effective. Instead of hoping members will respond to financial incentives, payers can actively orchestrate the behavioral change those incentives are designed to encourage.
Forward-thinking payers are already moving in this direction. The convergence of V-BID expansion, AI capabilities maturation, and growing evidence of population-scale behavioral intervention effectiveness creates a narrow window for competitive advantage.
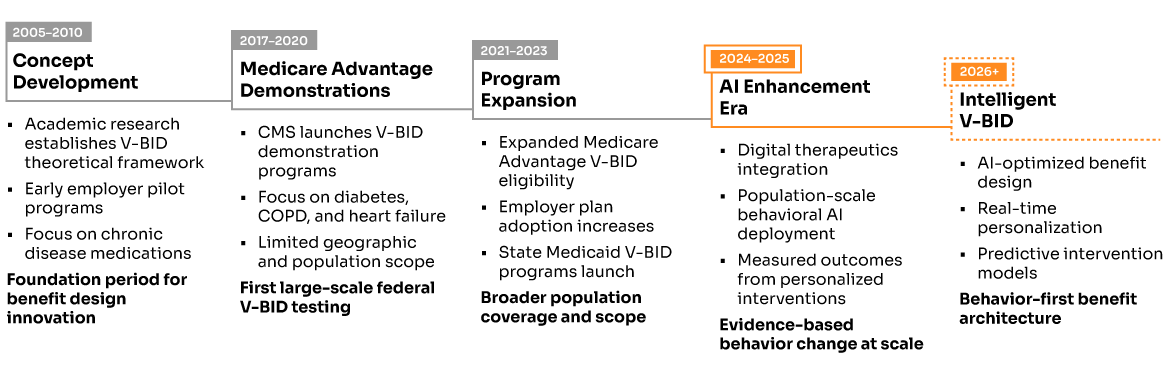
Medicare Advantage Plans
Participating in CMS V-BID demonstrations
Employer Adoption
Large employers implementing V-BID strategies
Medicaid Programs
State-level V-BID initiatives expanding
While V-BID programs have demonstrated promise in reducing financial barriers, Al-powered behavioral intervention represents the next evolution-transforming financial incentives into sustained behavior change through personalized context-aware digital therapeutics at population scale.)
Value-Based Insurance Design represented a crucial evolution from fee-for-service to outcome-focused healthcare financing. However, evidence suggests financial incentives alone cannot bridge the gap between knowing what to do and actually doing it.
The documented success of AI-powered behavioral interventions – demonstrated through controlled studies with tens of thousands of participants – shows that integrating behavioral science with financial incentives can make those incentives more effective. This isn’t about replacing V-BID programs, but enhancing them through behavioral intelligence that was previously unavailable.
Real-world deployments prove that AI-powered behavioral interventions can drive measurable health improvements at population scale. For payers, the question becomes how to integrate these proven capabilities with existing V-BID structures to maximize both member health outcomes and program effectiveness.
The evolution from financial incentives to behavioral influence represents a practical next step for healthcare organizations seeking to improve both clinical outcomes and operational efficiency.
The convergence of behavioral science, artificial intelligence, and value-based care represents healthcare’s next frontier. Organizations ready to move beyond traditional incentives to intelligent influence will define the industry’s next decade.
References:
1. Vrijens, B., et al. (2017). A comprehensive overview of medication adherence in middle-aged and elderly patients. European Heart Journal, 38(14), 1038-1047.
2.Thaler, R. H., & Sunstein, C. R. (2008). Nudge: Improving decisions about health, wealth, and happiness. Yale University Press.
3.Nahum-Shani, I., et al. (2018). Just-in-time adaptive interventions (JITAIs) in mobile health: key components and design principles for ongoing health behavior support. Annals of Behavioral Medicine, 52(6), 446-462.
4. Lustria, M. L. A., et al. (2013). A meta-analysis of web-delivered tailored health behavior change interventions. Journal of Health Communication, 18(9), 1039-1069.
5. Gallagher, K. M., & Updegraff, J. A. (2012). Health message framing effects on attitudes, intentions, and behavior: a meta-analytic review. Annals of Behavioral Medicine, 43(1), 101-116.
6. Cialdini, R. B., et al. (2006). Managing social norms for persuasive impact. Social Influence, 1(1), 3-15.
7. Chiam, J., Lim, A., & Teredesai, A. (2024). NudgeRank: Digital Algorithmic Nudging for Personalized Health. KDD ’24 Conference Proceedings.
8. CZ Platform Documentation (2025). Singapore Health Promotion Board Population Health Program Results.
Novex Alex Human behavior fascinates me—beautifully complex and unsolved, caught between our evolutionary instincts and today's rapidly changing world. There's a persistent gap between what's good for us, what we want, and what we actually do. Today's AI mirrors these same contradictions, yet tomorrow's self-learning technologies hold promise. I'm driven to embrace human diversity and complexity by building adaptive systems that meet people where they are, unlocking small personal changes without compromising autonomy. This approach isn't just compassionate—it's how each person's breakthrough becomes part of humanity's path to lasting transformation.

In our previous post, “From IDs to Meaning: The Case for Semantic Embeddings in Recommendation,” we introduced the concept of moving beyond ID-based representations to metadata-driven approaches and why it’s promising for domains like digital health and personalized health, where personalization needs to go beyond static IDs. By leveraging semantic embeddings derived from descriptive metadata using Large Language Models (LLMs), ID-free approaches aim to address common challenges such as cold-start problems, limited generalizability, and deployment complexity.
In this post, we move from concept to evidence. Our central question is: How do standard recommendation architectures perform when powered by ID-free semantic embeddings, compared to our current ID-based Knowledge Graph Attention Network (KGAT) recommender model?
For this evaluation, we selected models that reflect two distinct approaches to user and nudge representation: Baseline Models (both non-embedding and ID-based) and ID-Free Enhanced Models.
These models serve as foundational benchmarks for evaluating the value of more advanced, semantic embedding driven approaches:
These models represent traditional, well-established recommendation architectures, but with a key change: instead of learning embeddings from arbitrary IDs, they are adapted to operate on pre-computed semantic embeddings. These embeddings are generated using LLMs applied to rich metadata—such as user health profiles, behavioral signals, and nudge content—allowing us to directly assess how well semantic inputs perform when integrated into widely adopted architectures. The following models were selected as they represented a spectrum of RecSys architectures from collaborative filtering to sequential recommenders.
To ensure a robust and fair comparison, we conducted our experiments on our proprietary digital health recommendation dataset. The dataset encompasses 10 days of user interactions with various health nudges, alongside rich metadata for both users (e.g., demographics, health conditions, aggregated tracker data) and nudges (e.g., content text, categories, target behaviors, health nudges).
The following table summarizes the dataset statistics used for all models during training, validation, and testing.
| Statistic | Overall | Train | Validation | Test |
|---|---|---|---|---|
| # Users | 3,069 | 2,558 | 445 | 446 |
| # Nudges | 70 | 68 | 47 | 42 |
| # Interactions | 4,490 | 3,599 | 445 | 446 |
Table 1: Dataset Statistics for Overall, Train, Validation, and Test sets.
The ID-based KGAT model, unlike the other models, represents users, nudges, and related entities within a structured knowledge graph or health graph. As a result, its input includes a larger set of interconnected entities and relation types:
| Statistic | KGAT Input |
|---|---|
| # Nodes | 79,447 |
| # Edges | 564,429 |
Table 2: Knowledge Graph Structure for the KGAT Model.
Our evaluation followed a standard protocol:
To fully appreciate the distinct behaviors and performances observed in our benchmark, it is important to understand the fundamental differences in how our ID-based and ID-Free Enhanced models consume and represent data—especially in how they capture semantics, structure, and temporal context.
The ID-based KGAT model builds a knowledge graph where users, nudges, and related entities (e.g., markers, segments) are represented as unique nodes. Relationships between these nodes (e.g., has_marker, in_segment) form the graph’s edges. This structure allows the model to learn from multi-hop connections and structured metadata, but it encodes user and nudge attributes as a fixed snapshot, based on their state at the beginning of the input window.
In contrast, ID-free models use semantic embeddings that are dynamically generated from rich metadata at the time of each interaction. For example, a user’s embedding is derived from their behavioral attributes at the time the nudge was sent, while a nudge’s embedding reflects its actual content at the time (in case of any edits). This enables the model to adapt to temporal changes and deliver personalized recommendations using up-to-date information.
The table below summarizes key differences in how users and nudges are represented across the two approaches:
| Aspect | KGAT | ID-Free Enhanced Models |
|---|---|---|
| Interaction Data | Considers only the distinct nudges a user has interacted with (duplicates removed). | Includes all interactions, including repeated nudges, in the user's history. Sequential models also capture the order of interactions. |
| Temporal Adaptability | Static • Users and nudges are represented as a point-in-time snapshot based on their attributes at the start of the input window. • Limits the number of days of interaction data to avoid misalignment between interactions and associated user or nudge attributes (e.g. user health behaviors that change daily). | Dynamic • Semantic embeddings of users and nudges are updated as their attributes change. • Interactions are mapped to user and nudge embeddings using point-in-time joins, to associate an interaction event with the temporally-correct representation of the user and nudge. • No restriction on the amount of historical data used, since representations can reflect current states at any time. |
| User Representation | Graph-based connections to attributes (markers) and segments. | Semantic embeddings from the user's current attributes. |
| Nudge Representation | Graph-based connections to nudge attributes and target segments. | Semantic embeddings from the actual nudge content. |
We assessed performance using standard top-K recommendation metrics, specifically at K=3. These metrics quantify the quality of the top-ranked recommendations:
Let’s dive into how the models performed. The chart below presents the recommendation performance for each model across the key metrics.

Key Observations
These results suggest promising potential for ID-free embeddings to reshape how we approach recommendations—especially in dynamic, highly personalized domains like digital health, where user behaviors and preferences change on a daily basis. We repeated the experiments across multiple date ranges and consistently observed similar performance patterns, reinforcing the reliability of these insights.
Several key insights stand out:
This benchmark marks a pivotal step in our journey toward more adaptive and scalable recommendation systems. The strong performance of ID-Free Enhanced models signals a promising direction for the future of personalized digital health nudging. Our next steps will focus on:
These explorations will help us further assess the practical value of ID-free modeling and unlock its full potential—guiding our efforts to build an even more personalized, effective, and scalable nudge engine for digital health and personalized health.
References:
[1] X. Wang and e. al., “KGAT: Knowledge Graph Attention Network for Recommendation,” in KDD ’19, 2019.
[2] J. Chiam and e. al., “NudgeRank: Digital Algorithmic Nudging for Personalized Health,” in KDD ’24, 2024.
[3] S. Rendle and e. al., “BPR: Bayesian personalized ranking from implicit feedback,” in UAI ’09, 2009.
[4] X. He and e. al., “Neural Collaborative Filtering,” in WWW ’17, 2017.
[5] K. Mao and e. al., “SimpleX: A Simple and Strong Baseline for Collaborative Filtering,” in CIKM ’21, 2021.
[6] W.-C. Kang and e. al., “Self-Attentive Sequential Recommendation,” in ICDM ’18, 2018.
[7] L. Li and e. al., “A System for Massively Parallel Hyperparameter Tuning,” in MLSys 2020, 2020.

Recommender systems have become indispensable for navigating the vast digital landscape, helping users sift through large volumes of content, products, and services. In the realm of digital health, they play an increasingly vital role in delivering personalized nudges and guidance, enhancing individual engagement, and supporting better health outcomes.
Traditionally, these systems rely on ID-based embeddings, where each user and item (or in our case, each individual and health nudge) is assigned a unique numerical identifier. These IDs are then converted into dense vector representations using techniques like matrix factorization or collaborative filtering. While effective for individuals with interaction histories and popular nudges, this approach has notable limitations, particularly around generalizability and cold-start scenarios.
Enter ID-free embeddings: a promising shift enabled by advances in Large Language Models (LLMs). Instead of relying on arbitrary IDs, these embeddings are generated directly from the rich, descriptive metadata associated with individuals and health nudges—think nudge content (e.g., text, language, tonality), individual health behavior data (e.g., fitness tracker data, dietary logs), demographic data, and health conditions. By leveraging the advanced semantic understanding capabilities of LLMs, ID-free embeddings capture the inherent meaning and relationships within this textual and behavioral information, offering a more flexible and robust foundation for personalized health recommendations.
While conventional ID-based embeddings have been the mainstay of recommender systems for decades, it has several limitations:
At their core, ID-free embeddings transform the descriptive text and structured data associated with individuals and health nudges into high-dimensional numerical vectors, using a pre-trained LLM encoder. For example, a nudge like “Need a snack? Choose crunchy veggies like carrots to curb hunger without the calories.” Is fed into the LLM, which then outputs a dense vector representing the semantic essence of that nudge. Similarly, an individual’s health profile, including their activity levels from a fitness tracker, dietary preferences, or health goals, can be encoded into an individual embedding. This process allows the recommender system to understand what a nudge is designed to achieve, or who an individual is, based on their attributes and behaviors, rather than just a unique identifier.
In CueZen’s recommender setup:

The diagram above illustrates the differences between ID-based and ID-free embeddings. ID-based embedding vectors are created and randomly initialized for every unique individual and nudge. These embeddings are then iteratively updated (along with the model weights) during the training process of the recommender model, such that they optimize some objective or loss function. In the case of ID-free embeddings, user and nudge metadata are transformed into semantic embeddings via a pre-trained LLM, using only semantic content and not requiring any IDs. Model training proceeds as usual, where model weights are iteratively updated to optimize the objective or loss function.
This semantic approach offers several advantages for building robust and effective digital health recommender systems:
Recommender systems using ID-free embeddings are a rapidly evolving area of research. Built on the strong foundations of “traditional” recommender systems, the use of LLMs opens up many new possibilities in addressing previous limitations such as cold start, transferability and generalization across domains. As a result, researchers are increasingly interested in ID-free or modality-based approaches, which leverage semantic embeddings derived from content or behavioral signals.
The foundation for semantic retrieval models was laid by early neural recommender systems like DSSM [4] and the Youtube DNN model [5], which introduced architectures to map users and items into shared embedding spaces using behavioral and content features. Further advancements, such as Two-tower models [6] and attention-based architectures like DIN [7] and DIEN [8], significantly enhanced the ability to model user intent without relying solely on explicit ID representations.
Recent progress has pushed this direction further by demonstrating strong performance using purely semantic inputs. For instance, large language models (LLMs) have achieved state-of-the-art results for collaborative filtering using only textual item descriptions [9]. Similarly, Recformer [10] learns sequential user preferences by applying language modeling techniques directly to item content, thereby bypassing traditional ID lookups entirely.
Zero-shot and transferrable recommendation is another emerging area. ZESRec [11] performs well on cold-start tasks without requiring historical user data, while universal representation learning (UniSRec) [12] and vector-quantized embeddings (VQ-Rec) [13], demonstrate improved generalization across users and domains.
From a broader perspective, [14] present a comparative study between ID-based and modality-based recommenders, concluding that semantic models are not only viable alternatives but, in some cases, superior—especially in sparse or evolving environments. These findings align with our motivation to adopt ID-free recommendation strategies based on behavioral and content embeddings.
In the next few posts, we’ll go deeper into the following:
These explorations will help us assess the practical value of ID-free models and guide our next steps in improving our nudge engine.
References:
[1] S. Sanner and e. al., “Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences,” in RecSys, 2023.
[2] K. Zhang and e. al., “Learning ID-free Item Representation with Token Crossing for Multimodal Recommendation,” arXiv, 2024.
[3] Y. Li and e. al., “A Zero-Shot Generalization Framework for LLM-Driven Cross-Domain Sequential Recommendation,” arXiv, 2025.
[4] P.-S. Huang and e. al., “Learning deep structured semantic models for web search using clickthrough data,” in CIKM, 2013.
[5] P. Covington and e. al., “Deep Neural Networks for YouTube Recommendations,” in RecSys, 2016.
[6] X. Yi and e. al., “Sampling-bias-corrected neural modeling for large corpus item recommendations,” in RecSys, 2019.
[7] G. Zhou and e. al, “Deep Interest Network for Click-Through Rate Prediction,” in KDD, 2018.
[8] G. Zhou and e. al., “Deep interest evolution network for click-through rate prediction,” in AAAI, 2019.
[9] R. Li and e. al., “Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights,” arXiv, 2023.
[10] J. Li and e. al., “Text Is All You Need: Learning Language Representations for Sequential Recommendation,” arXiv, 2023.
[11] H. Ding and e. al., “Zero-Shot Recommender Systems,” Amazon Scienc, 2021.
[12] Y. Hou and e. al., “Towards Universal Sequence Representation Learning for Recommender Systems,” in KDD, 2022.
[13] Y. Hou and e. al., “Learning Vector-Quantized Item Representation for Transferable Sequential Recommenders,” in WWW, 2023.
[14] Z. Yuan and e. al., “Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited,” arXiv, 2023.